
后端深邃难觅迹
Maven
Maven是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。
它基于项目对象模型(Project Object Model , 简称: POM)的概念,通过一小段描述信息来管理项目的构建、报告和文档。
官网:https://maven.apache.org/
Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性组织。
开源项目:https://www.apache.org/index.html#projects-list
Maven的作用
- 依赖管理
- 统一项目结构
- 项目构建
依赖管理:
方便快捷的管理项目依赖的资源(jar包,平时使用需要手动下载并导入),避免版本冲突问题
当使用maven进行项目依赖(jar包)管理,则很方便的可以解决这个问题。 我们只需要在maven项目的pom.xml文件中,添加一段配置即可实现。
统一项目结构 :
- 提供标准、统一的项目结构
在项目开发中,当你使用不同的开发工具 (如:Eclipse、Idea),创建项目工程时,目录结构是不同的
若我们创建的是一个maven工程,是可以帮我们自动生成统一、标准的项目目录结构:

目录说明:
- src/main/java: java源代码目录
- src/main/resources: 配置文件信息
- src/test/java: 测试代码
- src/test/resources: 测试配置文件信息
项目构建 :
- maven提供了标准的、跨平台(Linux、Windows、MacOS) 的自动化项目构建方式
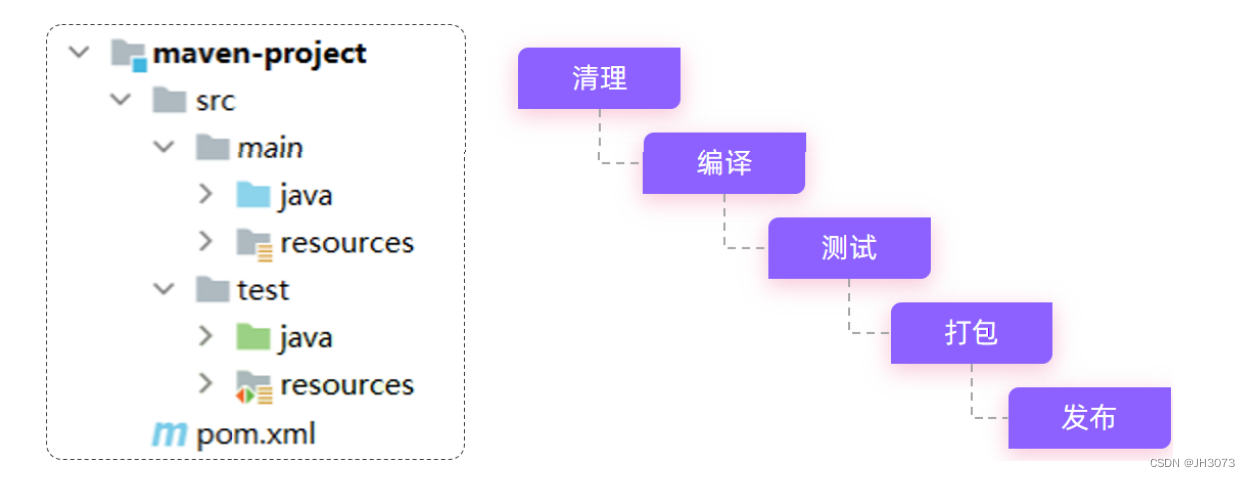
如上图所示我们开发了一套系统,代码需要进行编译、测试、打包、发布,这些操作如果需要反复进行就显得特别麻烦,而Maven提供了一套简单的命令来完成项目构建。
Maven模型
- 项目对象模型 (Project Object Model)
- 依赖管理模型(Dependency)
- 构建生命周期/阶段(Build lifecycle & phases)
1). 构建生命周期/阶段(Build lifecycle & phases)
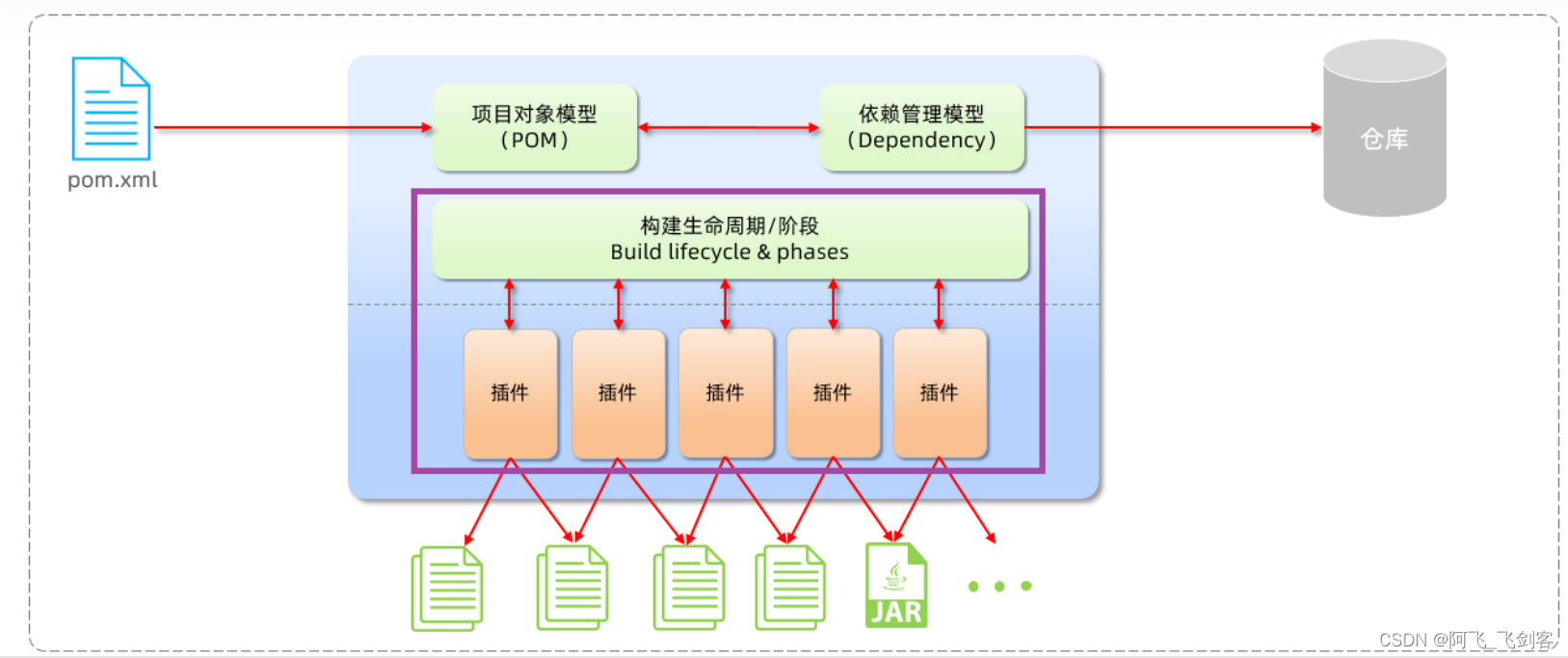
以上图中紫色框起来的部分,就是用来完成标准化构建流程 。当我们需要编译,Maven提供了一个编译插件供我们使用;当我们需要打包,Maven就提供了一个打包插件供我们使用等。
2). 项目对象模型 (Project Object Model)
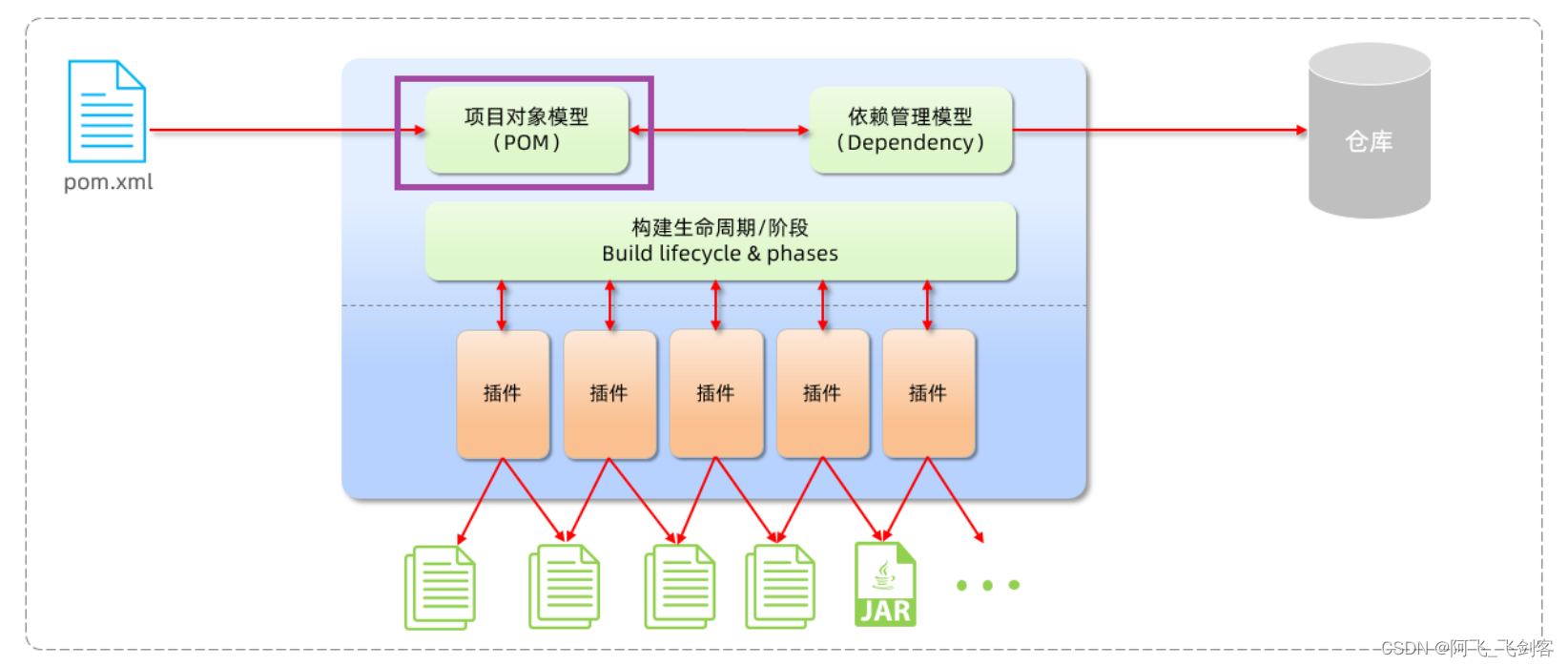
上图中紫色框起来的部分属于项目对象模型,将我们自己的项目抽象成一个对象模型,有自己专属的坐标。 什么是对象模型 POM (Project Object Model) :指的是项目对象模型,用来描述当前的maven项目。它是通过pom.xml文件来实现的。
1 |
|
- Maven 坐标主要由以下元素组成:
- groupId(必须): 项目组 ID,定义当前 Maven 项目隶属的组织或公司,通常是唯一的。它的取值一般是项目所属公司或组织的网址或 URL 的反写,例如 com.baidu.www。
- artifactId(必须): 项目 ID,通常是项目的名称。
- version(必须):版本。
- packaging(可选):项目的打包方式,默认值为 jar。
我们可以使用坐标来为自己的项目导入资源,同样,其他人也可以通过我们的项目坐标导入我们的资源。
3). 依赖管理模型(Dependency)
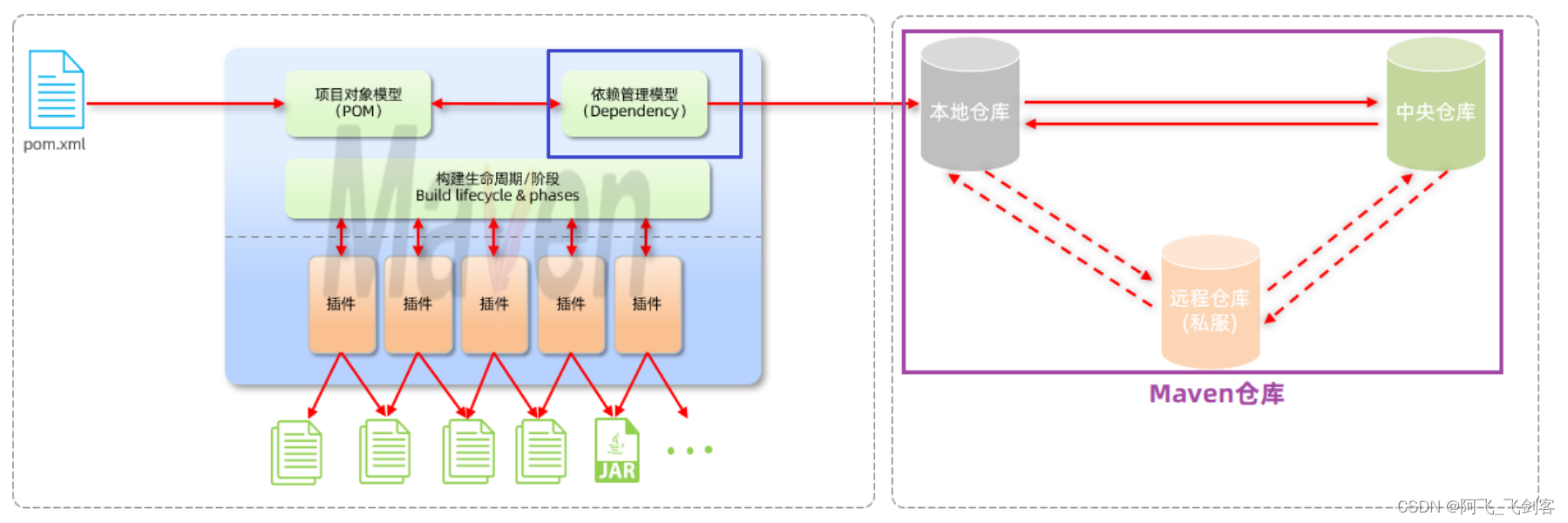
以上图中紫色框起来的部分属于依赖管理模型,是使用坐标来描述当前项目依赖哪些第三方jar包。当前项目所依赖的jar包需要从仓库中进行获取。 仓库:用于存储资源,管理各种jar包。
仓库的本质就是一个目录(文件夹),这个目录被用来存储开发中所有依赖(就是jar包)和插件。
Maven仓库分为: (1)本地仓库:自己计算机上的一个目录(用来存储jar包) (2)中央仓库:由Maven团队维护的全球唯一的。仓库地址:maven_repo (3)远程仓库(私服):一般由公司团队搭建的私有仓库
jar包的查找顺序为: 本地仓库 --> 远程仓库 --> 中央仓库
依赖管理
依赖配置
依赖:指当前项目运行所需要的jar包。一个项目中可以引入多个依赖:
例如:在当前工程中,我们需要用到logback来记录日志,此时就可以在maven工程的pom.xml文件中,引入logback的依赖。具体步骤如下:
在pom.xml中编写
<dependencies>标签在
<dependencies>标签中使用<dependency>引入坐标定义坐标的
groupId、artifactId、version
1 | <dependencies> |
- 点击刷新按钮,引入最新加入的坐标
- 刷新依赖:保证每一次引入新的依赖,或者修改现有的依赖配置,都可以加入最新的坐标
注意事项:
- 如果引入的依赖,在本地仓库中不存在,将会连接远程仓库 / 中央仓库,然后下载依赖(这个过程会比较耗时,耐心等待)
- 如果不知道依赖的坐标信息,可以到mvn的中央仓库(https://mvnrepository.com/)中搜索
依赖传递
传递性
早期我们没有使用maven时,向项目中添加依赖的jar包,需要把所有的jar包都复制到项目工程下。如下图所示,需要logback-classic时,由于logback-classic又依赖了logback-core和slf4j,所以必须把这3个jar包全部复制到项目工程下。
在maven中,当项目中需要使用logback-classic时,只需要在pom.xml配置文件中,添加logback-classic的依赖坐标即可。
在pom.xml文件中只添加了logback-classic依赖,但由于maven的依赖具有传递性,所以会自动把所依赖的其他jar包也一起导入。
排除依赖
假设A依赖B,B依赖C,如果A不想将C依赖进来,可以通过排除依赖来实现。
- 排除依赖:指主动断开依赖的资源。(被排除的资源无需指定版本)
1 | <dependency> |
依赖范围
在项目中导入依赖的jar包后,默认情况下,可以在任何地方使用。
如果希望限制依赖的使用范围,可以通过
作用范围:
- 主程序范围有效(main文件夹范围内)
- 测试程序范围有效(test文件夹范围内)
- 是否参与打包运行(package指令范围内)
1 | <!-- junit --> |
给junit依赖通过scope标签指定依赖的作用范围。 那么这个依赖就只能作用在测试环境,其他环境下不能使用。
scope标签的取值范围:
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
生命周期
Maven的生命周期就是为了对所有的构建过程进行抽象和统一。 描述了一次项目构建,经历哪些阶段。
在Maven出现之前,项目构建的生命周期就已经存在,软件开发人员每天都在对项目进行清理,编译,测试及部署。虽然大家都在不停地做构建工作,但公司和公司间、项目和项目间,往往使用不同的方式做类似的工作。
Maven从大量项目和构建工具中学习和反思,然后总结了一套高度完美的,易扩展的项目构建生命周期。这个生命周期包含了项目的清理,初始化,编译,测试,打包,集成测试,验证,部署和站点生成等几乎所有构建步骤。
Maven对项目构建的生命周期划分为3套(相互独立):

clean:清理工作。
default:核心工作。如:编译、测试、打包、安装、部署等。
site:生成报告、发布站点等。
三套生命周期又包含哪些具体的阶段呢, 我们来看下面这幅图:
我们看到这三套生命周期,里面有很多很多的阶段,这么多生命周期阶段,其实我们常用的并不多,主要关注以下几个:
• clean:移除上一次构建生成的文件
• compile:编译项目源代码
• test:使用合适的单元测试框架运行测试(junit)
• package:将编译后的文件打包,如:jar、war等
• install:安装项目到本地仓库
Maven的生命周期是抽象的,这意味着生命周期本身不做任何实际工作。在Maven的设计中,实际任务(如源代码编译)都交由插件来完成。
生命周期的顺序是:clean --> validate --> compile --> test --> package --> verify --> install --> site --> deploy
我们需要关注的就是:clean --> compile --> test --> package --> install
说明:在同一套生命周期中,我们在执行后面的生命周期时,前面的生命周期都会执行。
思考:当运行package生命周期时,clean、compile生命周期会不会运行?
clean不会运行,compile会运行。 因为compile与package属于同一套生命周期,而clean与package不属于同一套生命周期。
SpringBoot
1. HTTP协议
浏览器和服务器是按照HTTP协议进行数据通信的。
HTTP协议又分为:请求协议和响应协议
- 请求协议:浏览器将数据以请求格式发送到服务器
- 包括:请求行、请求头 、请求体
- 响应协议:服务器将数据以响应格式返回给浏览器
- 包括:响应行 、响应头 、响应体
请求协议
在HTTP1.1版本中,浏览器访问服务器的几种方式:
| 请求方式 | 请求说明 |
|---|---|
| GET | 获取资源。 向特定的资源发出请求。例:http://www.baidu.com/s?wd=nicccce |
| POST | 传输实体主体。 向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方式。 因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法,例如:DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。 |
| HEAD | 获得报文首部。 HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。通常用于确认URI的有效性及资源更新时间等。 |
| PUT | 传输文件。 PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。 |
| DELETE | 删除文件。 请求服务器删除Request-URI所标识的资源 |
| TRACE | 追踪路径。 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | 要求用隧道协议连接代理。 HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
在我们实际应用中常用的也就是 :GET、POST
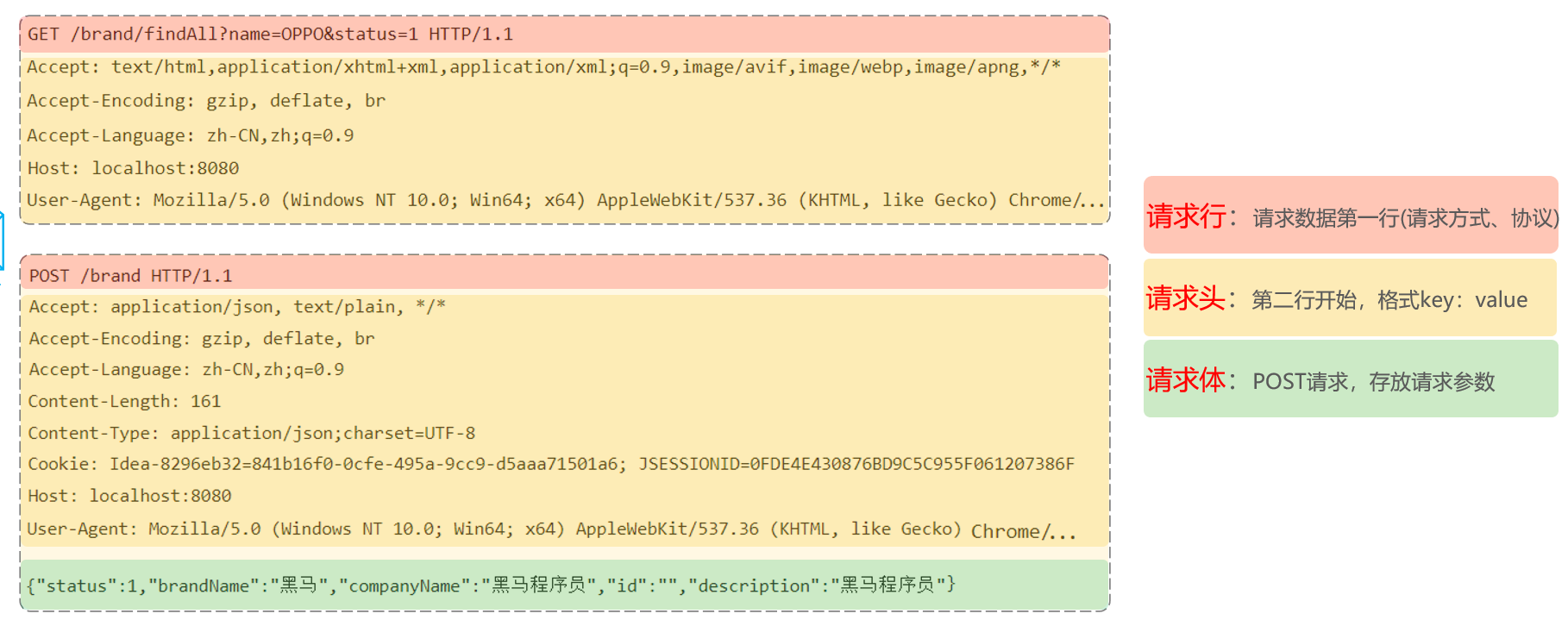
GET方式的请求协议:
请求行 :HTTP请求中的第一行数据。由:
请求方式、资源路径、协议/版本组成(之间使用空格分隔)- 请求方式:GET
- 资源路径:/brand/findAll?name=OPPO&status=1
- 请求路径:/brand/findAll
- 请求参数:name=OPPO&status=1
- 请求参数是以key=value形式出现
- 多个请求参数之间使用
&连接
- 请求路径和请求参数之间使用
?连接
- 协议/版本:HTTP/1.1
- 请求方式:GET
请求头 :第二行开始,上 图黄色部分内容就是请求头。格式为key: value形式
- http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
常见的HTTP请求头有:
1
2
3
4
5
6
7
8
9
10
11
12
13Host: 表示请求的主机名
User-Agent: 浏览器版本。 例如:Chrome浏览器的标识类似Mozilla/5.0 ...Chrome/79 ,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...)like Gecko
Accept:表示浏览器能接收的资源类型,如text/*,image/*或者*/*表示所有;
Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate等。
Content-Type:请求主体的数据类型
Content-Length:数据主体的大小(单位:字节)
举例说明:服务端可以根据请求头中的内容来获取客户端的相关信息,有了这些信息服务端就可以处理不同的业务需求。
比如:
- 不同浏览器解析HTML和CSS标签的结果会有不一致,所以就会导致相同的代码在不同的浏览器会出现不同的效果
- 服务端根据客户端请求头中的数据获取到客户端的浏览器类型,就可以根据不同的浏览器设置不同的代码来达到一致的效果(这就是我们常说的浏览器兼容问题)
- 请求体 :存储请求参数
- GET请求的请求参数在请求行中,故不需要设置请求体
POST方式的请求协议:
- 请求行(以上图中红色部分):包含请求方式、资源路径、协议/版本
- 请求方式:POST
- 资源路径:/brand
- 协议/版本:HTTP/1.1
- 请求头(以上图中黄色部分)
- 请求体(以上图中绿色部分) :存储请求参数
- 请求体和请求头之间是有一个空行隔开(作用:用于标记请求头结束)
GET请求和POST请求的区别:
| 区别方式 | GET请求 | POST请求 |
|---|---|---|
| 请求参数 | 请求参数在请求行中。 例:/brand/findAll?name=OPPO&status=1 |
请求参数在请求体中 |
| 请求参数长度 | 请求参数长度有限制(浏览器不同限制也不同) | 请求参数长度没有限制 |
| 安全性 | 安全性低。原因:请求参数暴露在浏览器地址栏中。 | 安全性相对高 |
响应协议
格式
与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体
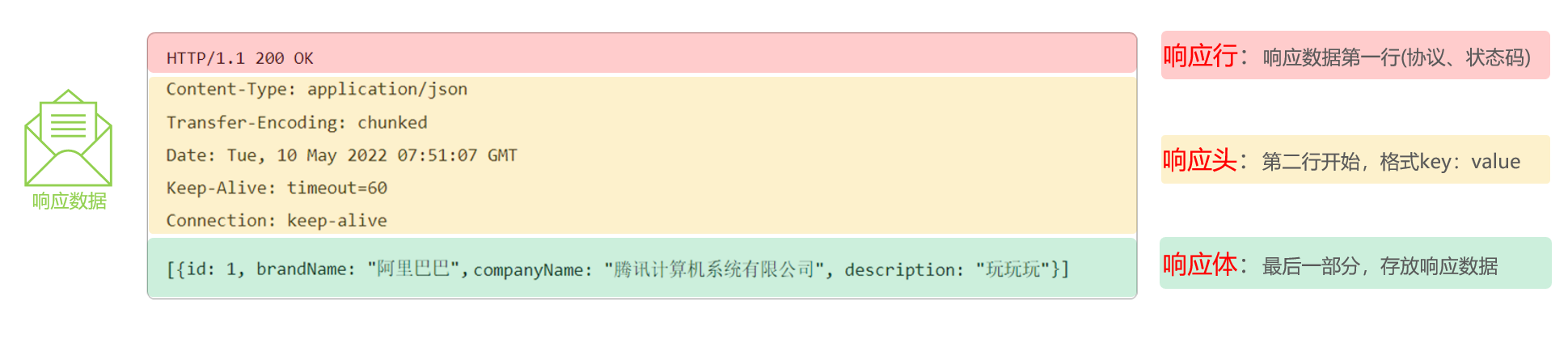
响应行(以上图中红色部分):响应数据的第一行。响应行由
协议及版本、响应状态码、状态码描述组成- 协议/版本:HTTP/1.1
- 响应状态码:200
- 状态码描述:OK
响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式
- http是个无状态的协议,所以可以在请求头和响应头中设置一些信息和想要执行的动作,这样,对方在收到信息后,就可以知道你是谁,你想干什么
常见的HTTP响应头有:
1
2
3
4
5
6
7
8
9Content-Type:表示该响应内容的类型,例如text/html,image/jpeg ;
Content-Length:表示该响应内容的长度(字节数);
Content-Encoding:表示该响应压缩算法,例如gzip ;
Cache-Control:指示客户端应如何缓存,例如max-age=300表示可以最多缓存300秒 ;
Set-Cookie: 告诉浏览器为当前页面所在的域设置cookie ;响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 --- 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
状态码大全:https://cloud.tencent.com/developer/chapter/13553
关于响应状态码,我们先主要认识三个状态码,其余的等后期用到了再去掌握:
- 200 ok 客户端请求成功
- 404 Not Found 请求资源不存在
- 500 Internal Server Error 服务端发生不可预期的错误
2.内嵌Tomcat
问题:为什么我们之前书写的SpringBoot入门程序中,并没有把程序部署到Tomcat的webapps目录下,也可以运行呢?
因为在我们的SpringBoot中,引入了web运行环境(也就是引入spring-boot-starter-web起步依赖),其内部已经集成了内置的Tomcat服务器。
我们可以通过IDEA开发工具右侧的maven面板中,就可以看到当前工程引入的依赖。其中已经将Tomcat的相关依赖传递下来了,也就是说在SpringBoot中可以直接使用Tomcat服务器。
当我们运行SpringBoot的引导类时(运行main方法),就会看到命令行输出的日志,其中占用8080端口的就是Tomcat。
3.请求响应
请求
简单参数
简单参数:在向服务器发起请求时,向服务器传递的是一些普通的请求数据。
我们在这里讲解两种方式:
原始方式
在原始的Web程序当中,需要通过Servlet中提供的API:HttpServletRequest(请求对象),获取请求的相关信息。比如获取请求参数:
Tomcat接收到http请求时:把请求的相关信息封装到HttpServletRequest对象中
在Controller中,我们要想获取Request对象,可以直接在方法的形参中声明 HttpServletRequest 对象。然后就可以通过该对象来获取请求信息:
1 | //根据指定的参数名获取请求参数的数据值 |
1 |
|
以上这种方式,我们仅做了解。(在以后的开发中不会使用到)
SpringBoot方式
在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
1 |
|
不论是GET请求还是POST请求,对于简单参数来讲,只要保证==请求参数名和Controller方法中的形参名保持一致==,就可以获取到请求参数中的数据值。
@RequestParam
@RequestParam在Spring
MVC中用于从HTTP请求中提取参数,并绑定到控制器方法的参数上。无论是在GET请求还是POST请求中,@RequestParam的基本功能都是相似的,但根据请求类型的不同,它的使用方式和目的可能有所不同。
在GET请求中:
在GET请求中,参数通常附加在URL的查询字符串上。@RequestParam用于从查询字符串中提取参数。例如,对于URL
http://example.com/search?keyword=spring,你可以使用@RequestParam来获取keyword参数的值。
1 |
|
在这个例子中,当GET请求发送到/search路径时,Spring
MVC会自动从查询字符串中提取keyword参数,并将其值绑定到search方法的keyword参数上。
在POST请求中:
在POST请求中,参数通常包含在请求体中,但@RequestParam也可以用于从URL的查询字符串中提取参数,如果参数是以这种方式传递的话。然而,更常见的是使用@RequestBody来解析请求体中的参数,尤其是当参数是复杂类型(如JSON对象)时。
但是,如果POST请求的参数是以application/x-www-form-urlencoded格式编码的(即表单数据),则可以使用@RequestParam来提取这些参数。这种情况下,参数会像GET请求中的查询字符串一样被编码,并附加在请求体中。
1 |
|
在这个例子中,当POST请求发送到/login路径时,并且请求体中包含以application/x-www-form-urlencoded格式编码的username和password参数时,Spring
MVC会自动提取这些参数的值,并将它们绑定到login方法的相应参数上。
总的来说,@RequestParam在GET请求中主要用于从URL查询字符串中提取参数,而在POST请求中则可以用于从请求体或URL查询字符串中提取以application/x-www-form-urlencoded格式编码的参数。然而,在处理POST请求中的复杂数据类型时,更常见的是使用@RequestBody注解。
如果方法形参名称与请求参数名称不一致,运行不会报错。 controller方法中的username值为:null,age值为20
对于简单参数来讲,请求参数名和controller方法中的形参名不一致时,无法接收到请求数据
解决方法:在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。
1 |
|
注意:
@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错
如果该参数是可选的,可以将required属性设置为false
1 |
|
设置默认值
可以通过@RequestParam设置默认值
1 |
|
实体参数
在使用简单参数做为数据传递方式时,前端传递了多少个请求参数,后端controller方法中的形参就要书写多少个。如果请求参数比较多,通过上述的方式一个参数一个参数的接收,会比较繁琐。
此时,我们可以考虑将请求参数封装到一个实体类对象中。 要想完成数据封装,需要遵守如下规则:请求参数名与实体类的属性名相同
简单实体对象
定义POJO实体类:
1 | public class User { |
Controller方法:
1 |
|
- 参数名和实体类属性名不一致时,对应属性是null
复杂实体对象
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
- User类中有一个Address类型的属性(Address是一个实体类)
复杂实体对象的封装,需要遵守如下规则:
- 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。
定义POJO实体类:
- Address实体类
1 | public class Address { |
- User实体类
1 | public class User { |
Controller方法:
1 |
|
需要传递的:
name
age
address.province
address.city
数组集合参数的使用场景:在HTML的表单中,有一个表单项是支持多选的(复选框),可以提交选择的多个值。
多个值是怎么提交的呢?其实多个值也是一个一个的提交。是参数名一样,但参数值不同提交多个 。
在前端请求时,有两种传递形式:
方式一:
http://localhost:8080/arrayParam?hobby=game&hobby=java
方式二:http://localhost:8080/arrayParam?hobby=game,java
后端程序接收上述多个值的方式有两种:
- 数组
- 集合
数组参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
Controller方法:
1 |
|
集合参数
集合参数:请求参数名与形参集合对象名相同且请求参数为多个,@RequestParam 绑定参数关系
- 默认情况下,请求中参数名相同的多个值,是封装到数组。如果要封装到集合,要使用@RequestParam绑定参数关系
Controller方法:
1 |
|
日期参数
上述演示的都是一些普通的参数,在一些特殊的需求中,可能会涉及到日期类型数据的封装。
因为日期的格式多种多样(如:2022-12-12 10:05:45 、2022/12/12 10:05:45),那么对于日期类型的参数在进行封装的时候,需要通过@DateTimeFormat注解,以及其pattern属性来设置日期的格式。
http://localhost:8080/dateParam?updateTime=2022-12-12 10:05:45
- @DateTimeFormat注解的pattern属性中指定了哪种日期格式,前端的日期参数就必须按照指定的格式传递。
- 后端controller方法中,需要使用Date类型或LocalDateTime类型,来封装传递的参数。
Controller方法:
1 |
|
JSON参数
在学习前端技术时,我们有讲到过JSON,而在前后端进行交互时,如果是比较复杂的参数,前后端通过会使用JSON格式的数据进行传输。 (JSON是开发中最常用的前后端数据交互方式)
我们学习JSON格式参数,主要从以下两个方面着手:
- Postman在发送请求时,如何传递json格式的请求参数
- 在服务端的controller方法中,如何接收json格式的请求参数
Postman发送JSON格式数据:
服务端Controller方法接收JSON格式数据:
传递json格式的参数,在Controller中会使用实体类进行封装。
封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
@RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
实体类:Address
1 | public class Address { |
实体类:User
1 | public class User { |
Controller方法:
1 |
|
路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
1 | http://localhost:8080/user/1 |
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
学习路径参数呢,主要掌握在后端的controller方法中,如何接收路径参数。
路径参数:
前端:通过请求URL直接传递参数
http://localhost:8080/path/100后端:使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
Controller方法:
1 |
|
传递多个路径参数:
URL:http://localhost:880/path/1/ITCAST
Controller方法:
1 |
|
响应
@ResponseBody
在我们前面所编写的controller方法中,都已经设置了响应数据。
1 | return "Hello World" //响应给浏览器的结果 |
controller方法中的return的结果,怎么就可以响应给浏览器呢?
答案:使用@ResponseBody注解
@ResponseBody注解:
- 类型:方法注解、类注解
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
但是在我们所书写的Controller中,只在类上添加了@RestController注解、方法添加了@RequestMapping注解,并没有使用@ResponseBody注解,怎么给浏览器响应呢?
1 |
|
原因:在类上添加的@RestController注解,是一个组合注解。
@RestController=@Controller+@ResponseBody
@RestController源码:
1 | //元注解(修饰注解的注解) |
结论:在类上添加@RestController就相当于添加了@ResponseBody注解。
- 类上有@RestController注解或@ResponseBody注解时:表示当前类下所有的方法返回值做为响应数据
- 方法的返回值,如果是一个POJO对象或集合时,会先转换为JSON格式,在响应给浏览器
下面我们来测试下响应数据:
1 |
|
在服务端响应了一个对象或者集合,那私前端获取到的数据是什么样子的呢?
1 | { |
1 | [ |
统一响应结果
我们在前面所编写的这些Controller方法中,返回值各种各样,没有任何的规范。
在真实的项目开发中,无论是哪种方法,我们都会定义一个统一的返回结果。方案如下:
统一的返回结果使用类来描述,在这个结果中包含:
响应状态码:当前请求是成功,还是失败
状态码信息:给页面的提示信息
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息。代码如下:
1 | public class Result { |
改造Controller:
1 |
|
使用Postman测试:
在服务端响应了一个对象或者集合,那私前端获取到的数据是什么样子的呢?测试效果如下:
1 | { |
1 | { |
分层解耦
三层架构
在我们进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
其实我们之前的程序的处理逻辑呢,从组成上看可以分为三个部分:
- 数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
- 逻辑处理:负责业务逻辑处理的代码。
- 请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
按照上述的三个组成部分,在我们项目开发中呢,可以将代码分为三层:
- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
基于三层架构的程序执行流程:
- 前端发起的请求,由Controller层接收(Controller响应数据给前端)
- Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
- Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
- Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
思考:按照三层架构的思想,如何要对业务逻辑(Service层)进行变更,会影响到Controller层和Dao层吗?
答案:不会影响。 (程序的扩展性、维护性变得更好了)
代码拆分
我们使用三层架构思想,来改造下之前的程序:
- 控制层包名:xxxx.controller
- 业务逻辑层包名:xxxx.service
- 数据访问层包名:xxxx.dao

控制层:接收前端发送的请求,对请求进行处理,并响应数据
1 |
|
业务逻辑层:处理具体的业务逻辑
- 业务接口
1 | //业务逻辑接口(制定业务标准) |
- 业务实现类
1 | //业务逻辑实现类(按照业务标准实现) |
数据访问层:负责数据的访问操作,包含数据的增、删、改、查
- 数据访问接口
1 | //数据访问层接口(制定标准) |
- 数据访问实现类
1 | //数据访问实现类 |
三层架构的好处:
- 复用性强
- 便于维护
- 利用扩展
分层解耦
刚才我们学习过程序分层思想了,接下来呢,我们来学习下程序的解耦思想。
解耦:解除耦合。
耦合问题
解软件开发涉及到的两个概念:内聚和耦合。
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
程序中高内聚的体现:
- EmpServiceA类中只编写了和员工相关的逻辑处理代码
程序中耦合代码的体现:
- 把业务类变为EmpServiceB时,需要修改controller层中的代码
高内聚、低耦合的目的是使程序模块的可重用性、移植性大大增强。
解耦思路
之前我们在编写代码时,需要什么对象,就直接new一个就可以了。 这种做法呢,层与层之间代码就耦合了,当service层的实现变了之后, 我们还需要修改controller层的代码。
那应该怎么解耦呢?
首先不能在EmpController中使用new对象。
此时,就存在另一个问题了,不能new,就意味着没有业务层对象(程序运行就报错),怎么办呢?
- 我们的解决思路是:
- 提供一个容器,容器中存储一些对象(例:EmpService对象)
- controller程序从容器中获取EmpService类型的对象
- 我们的解决思路是:
我们想要实现上述解耦操作,就涉及到Spring中的两个核心概念:
控制反转: Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转。
对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
依赖注入: Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
程序运行时需要某个资源,此时容器就为其提供这个资源。
例:EmpController程序运行时需要EmpService对象,Spring容器就为其提供并注入EmpService对象
IOC容器中创建、管理的对象,称之为:bean对象
IOC&DI
上面我们引出了Spring中IOC和DI的基本概念,下面我们就来具体学习下IOC和DI的代码实现。
入门
- 思路:
- 删除Controller层、Service层中new对象的代码
- Service层及Dao层的实现类,交给IOC容器管理
- 为Controller及Service注入运行时依赖的对象
- Controller程序中注入依赖的Service层对象
- Service程序中注入依赖的Dao层对象
第1步:删除Controller层、Service层中new对象的代码
第2步:Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
第3步:为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象
完整的三层代码:
- Controller层:
1 |
|
- Service层:
1 | //将当前对象交给IOC容器管理,成为IOC容器的bean |
- Dao层:
1 | //将当前对象交给IOC容器管理,成为IOC容器的bean |
bean的声明
前面我们提到IOC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对象。IOC容器创建的对象称为bean对象。
在之前的入门案例中,要把某个对象交给IOC容器管理,需要在类上添加一个注解:@Component
而Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
- @Controller (标注在控制层类上)
- @Service (标注在业务层类上)
- @Repository (标注在数据访问层类上)
修改入门案例代码:
- Controller层:
1 | //@RestController = @Controller + @ResponseBody |
- Service层:
1 |
|
Dao层:
1 |
|
要把某个对象交给IOC容器管理,需要在对应的类上加上如下注解之一:
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少) |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
在IOC容器中,每一个Bean都有一个属于自己的名字,可以通过注解的value属性指定bean的名字。如果没有指定,默认为类名首字母小写。
注意事项:
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
- 使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
组件扫描
使用前面学习的四个注解声明的bean,不一定会生效(原因:bean想要生效,还需要被组件扫描)
- 使用四大注解声明的bean,要想生效,还需要被组件扫描注解@ComponentScan扫描
@ComponentScan注解虽然没有显式配置,但是实际上已经包含在了引导类声明注解 @SpringBootApplication 中,默认扫描的范围是SpringBoot启动类所在包及其子包。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public SpringBootApplication {...}
解决方案:手动添加@ComponentScan注解,指定要扫描的包 (==仅做了解,不推荐==)
1
2
3
public class ManagementUserApplication {...}
推荐做法(如下图):
- 将我们定义的controller,service,dao这些包呢,都放在引导类所在包com.nicccce的子包下,这样我们定义的bean就会被自动的扫描到
DI细节
依赖注入,是指IOC容器要为应用程序去提供运行时所依赖的资源,而资源指的就是对象。
在入门程序案例中,我们使用了@Autowired这个注解,完成了依赖注入的操作,而这个Autowired翻译过来叫:自动装配。
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
入门程序举例:在EmpController运行的时候,就要到IOC容器当中去查找EmpService这个类型的对象,而我们的IOC容器中刚好有一个EmpService这个类型的对象,所以就找到了这个类型的对象完成注入操作。
那如果在IOC容器中,存在多个相同类型的bean对象,程序运行会报错
Spring提供了以下几种解决方案:
@Primary
@Qualifier
@Resource
使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
1 | //让当前bean生效 |
使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。
- @Qualifier注解不能单独使用,必须配合@Autowired使用
1 |
|
使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
1 |
|
@Autowird 与 @Resource的区别
- @Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired 默认是按照类型注入,而@Resource是按照名称注入
- 本文作者: NICK
- 本文链接: https://nicccce.github.io/TechNotes/Back-End-1/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!