
JPA
JPA全称Java Persistence API(2019年重新命名为 Jakarta Persistence API ),是Sun官方提出的一种ORM规范。
O:Object R: Relational M:mapping
作用
1.简化持久化操作的开发工作:让开发者从繁琐的 JDBC 和 SQL 代码中解脱出来,直接面向对象持久化操作。
2.Sun希望持久化技术能够统一,实现天下归一:如果你是基于JPA进行持久化你可以随意切换数据库。
该规范为我们提供了:
1)ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对
象持久化到数据库表中;
如:
@Entity、@Table、@Id与@Column等注解。2)JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和
SQL代码中解脱出来。
如:
entityManager.merge(T t);3)JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
如:
from Student s where s.name = ?So: JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。
Hibernate与JPA:
所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。
和mybatis区别:
mybatis:
小巧、方便?、高效、简单、直接、半自动
半自动的ORM框架,
小巧: mybatis就是jdbc封装
在国内更流行。
场景: 在业务比较复杂系统进行使用,
hibernate:
强大、方便、高效、(简单)复杂、绕弯子、全自动
全自动的ORM框架,
强大:根据ORM映射生成不同SQL
在国外更流。
场景: 在业务相对简单的系统进行使用,随着微服务的流行。
Jpa示例
以下内容实际没啥用,只是展示jpa的特色罢了,可以跳过
1、添加META-INF.xml
1 |
|
2、测试代码:
1 | import com.xushu.pojo.Customer; |
jpa的对象4种状态
- 临时状态:刚创建出来,∙没有与entityManager发生关系,没有被持久化,不处于entityManager中的对象
- 持久状态:∙与entityManager发生关系,已经被持久化,您可以把持久化状态当做实实在在的数据库记录。
- 删除状态:执行remove方法,事物提交之前
- 游离状态:游离状态就是提交到数据库后,事务commit后实体的状态,因为事务已经提交了,此时实体的属性任你如何改变,也不会同步到数据库,因为游离是没人管的孩子,不在持久化上下文中。
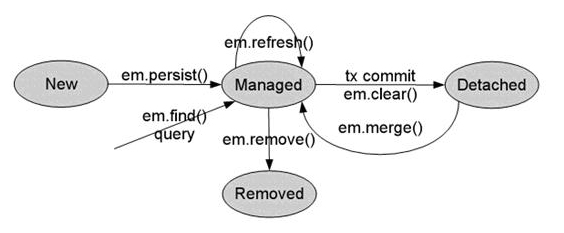
public void persist(Object entity)
persist方法可以将实例转换为managed(托管)状态。在调用flush()方法或提交事物后,实例将会被插入到数据库中。
对不同状态下的实例A,persist会产生以下操作:
如果A是一个new状态的实体,它将会转为managed状态;
如果A是一个managed状态的实体,它的状态不会发生任何改变。但是系统仍会在数据库执行INSERT操作;
如果A是一个removed(删除)状态的实体,它将会转换为受控状态;
如果A是一个detached(分离)状态的实体,该方法会抛出IllegalArgumentException异常,具体异常根据不同的JPA实现有关。
public void merge(Object entity)
merge方法的主要作用是将用户对一个detached状态实体的修改进行归档,归档后将产生一个新的managed状态对象。
对不同状态下的实例A,merge会产生以下操作:
如果A是一个detached状态的实体,该方法会将A的修改提交到数据库,并返回一个新的managed状态的实例A2;
如果A是一个new状态的实体,该方法会产生一个根据A产生的managed状态实体A2;
如果A是一个managed状态的实体,它的状态不会发生任何改变。但是系统仍会在数据库执行UPDATE操作;
如果A是一个removed状态的实体,该方法会抛出IllegalArgumentException异常。
public void refresh(Object entity)
refresh方法可以保证当前的实例与数据库中的实例的内容一致。
对不同状态下的实例A,refresh会产生以下操作:
如果A是一个new状态的实例,不会发生任何操作,但有可能会抛出异常,具体情况根据不同JPA实现有关;
如果A是一个managed状态的实例,它的属性将会和数据库中的数据同步;
如果A是一个removed状态的实例,该方法将会抛出异常: Entity not managed
如果A是一个detached状态的实体,该方法将会抛出异常。
public void remove(Object entity)
remove方法可以将实体转换为removed状态,并且在调用flush()方法或提交事物后删除数据库中的数据。
对不同状态下的实例A,remove会产生以下操作:
如果A是一个new状态的实例,A的状态不会发生任何改变,但系统仍会在数据库中执行DELETE语句;
如果A是一个managed状态的实例,它的状态会转换为removed;
如果A是一个removed状态的实例,不会发生任何操作;
如果A是一个detached状态的实体,该方法将会抛出异常。
Spring data JPA
Spring Data JPA, part of the larger Spring Data family, makes it easy to easily implement JPA based repositories. This module deals with enhanced support for JPA based data access layers. It makes it easier to build Spring-poweredapplications that use data access technologies.
Implementing a data access layer of an application has been cumbersome for quite a while. Too much boilerplate codehas to be written to execute simple queries as well as perform pagination, and auditing. Spring Data JPA aims tosignificantly improve the implementation of data access layers by reducing the effort to the amount that’s actuallyneeded. As a developer you write your repository interfaces, including custom finder methods, and Spring will provide theimplementation automatically.
Spring Data JPA 是更大的 Spring Data 系列的一部分,可以轻松实现基于 JPA 的repositories。该模块处理对基于 JPA 的数据访问层的增强支持。它使构建使用数据访问技术的 Spring 驱动的应用程序变得更加容易。
实现应用程序的数据访问层已经很麻烦了。必须编写太多样板代码来执行简单的查询以及执行分页和审计。Spring Data JPA 旨在改进数据访问层的实现以提升开发效率。作为开发人员,您编写存储库接口,包括自定义 finder 方法,Spring 将自动提供实现。
spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的规则进行【方法命名】去写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
依赖
最好在父maven项目中设置spring data统一版本管理依赖: 因为不同的spring data子项目发布时间版本不一样,你自己维护很麻烦, 这样不同的spring data子项目能保证是统一版本.
1 | <!--统一管理SpringData子项目的版本--> |
1 | <!-- 起步依赖 --> |
CrudRepository
Spring Data repository 抽象的目标是显着减少为各种持久性存储实现数据访问层所需的样板代码量。
创建实体类
1 | package com.nicccce.pojo; |
创建接口
1 | /** |
CrudRepository:
1 |
|
在CrudRepository 之上,有一个PagingAndSortingRepository抽象,它添加了额外的方法来简化对实体的分页和排序访问:
1 | //分页 |
自定义操作
jpql | 原生SQL
@Query查询如果返回单个实体 就用pojo接收 , 如果是多个需要通过集合
- 参数设置方式
索引 : ?数字
具名: :参数名 结合@Param注解指定参数名字
- 增删改:
要加上事务的支持:
如果是插入方法:一定只能在hibernate下才支持 (Insert into ... select )
1 | // 通常会放在业务逻辑层上面去声明,增删改操作必须要加,否则会报错 |
1 | package com.nicccce.repositories; |
规定方法名
- 支持的查询方法主题关键字(前缀)
- 决定当前方法作用
- 只支持查询和删除
| Keyword | Description |
|---|---|
find…By,
read…By, get…By, query…By,
search…By, stream…By |
一般查询方法,通常返回 repository
类型、Collection 或 Streamable 子类型或result
wrapper,如 Page、GeoResults
或任何其他store特定的result wrapper。可以作为
findBy…、findMyDomainTypeBy…
或与其他关键字结合使用。 |
exists…By |
Exists 投影,通常返回一个
boolean 结果。 |
count…By |
返回数字结果的count投影。 |
delete…By,
remove…By |
删除查询方法要么不返回结果(void),要么返回删除数量。 |
…First<number>…,
…Top<number>… |
将查询结果限制在第一个
<number> 的结果。这个关键词可以出现在主语中
find(以及其他关键词)和 by
之间的任何地方。 |
…Distinct… |
使用 distinct
查询,只返回唯一的结果。请咨询特定store的文档是否支持该功能。这个关键字可以出现在
find(和其他关键字)和 by
之间的任何地方。 |
- 支持的查询方法谓词关键字和修饰符
- 决定查询条件
| 逻辑关键字 | 关键字表达式 |
|---|---|
AND |
And |
OR |
Or |
AFTER |
After,
IsAfter |
BEFORE |
Before,
IsBefore |
CONTAINING |
Containing,
IsContaining, Contains |
BETWEEN |
Between,
IsBetween |
ENDING_WITH |
EndingWith,
IsEndingWith, EndsWith |
EXISTS |
Exists |
FALSE |
False,
IsFalse |
GREATER_THAN |
GreaterThan,
IsGreaterThan |
GREATER_THAN_EQUALS |
GreaterThanEqual,
IsGreaterThanEqual |
IN |
In, IsIn |
IS |
Is, Equals, (or
no keyword) |
IS_EMPTY |
IsEmpty,
Empty |
IS_NOT_EMPTY |
IsNotEmpty,
NotEmpty |
IS_NOT_NULL |
NotNull,
IsNotNull |
IS_NULL |
Null,
IsNull |
LESS_THAN |
LessThan,
IsLessThan |
LESS_THAN_EQUAL |
LessThanEqual,
IsLessThanEqual |
LIKE |
Like,
IsLike |
NEAR |
Near,
IsNear |
NOT |
Not, IsNot |
NOT_IN |
NotIn,
IsNotIn |
NOT_LIKE |
NotLike,
IsNotLike |
REGEX |
Regex,
MatchesRegex, Matches |
STARTING_WITH |
StartingWith,
IsStartingWith, StartsWith |
TRUE |
True,
IsTrue |
WITHIN |
Within,
IsWithin |
样例:
| Keyword | Sample | JPQL snippet |
|---|---|---|
Distinct |
findDistinctByLastnameAndFirstname |
select distinct … where x.lastname = ?1 and x.firstname = ?2 |
And |
findByLastnameAndFirstname |
… where x.lastname = ?1 and x.firstname = ?2 |
Or |
findByLastnameOrFirstname |
… where x.lastname = ?1 or x.firstname = ?2 |
Is, Equals |
findByFirstname,findByFirstnameIs,findByFirstnameEquals |
… where x.firstname = ?1 |
Between |
findByStartDateBetween |
… where x.startDate between ?1 and ?2 |
LessThan |
findByAgeLessThan |
… where x.age < ?1 |
LessThanEqual |
findByAgeLessThanEqual |
… where x.age <= ?1 |
GreaterThan |
findByAgeGreaterThan |
… where x.age > ?1 |
GreaterThanEqual |
findByAgeGreaterThanEqual |
… where x.age >= ?1 |
After |
findByStartDateAfter |
… where x.startDate > ?1 |
Before |
findByStartDateBefore |
… where x.startDate < ?1 |
IsNull,
Null |
findByAge(Is)Null |
… where x.age is null |
IsNotNull,
NotNull |
findByAge(Is)NotNull |
… where x.age not null |
Like |
findByFirstnameLike |
… where x.firstname like ?1 |
NotLike |
findByFirstnameNotLike |
… where x.firstname not like ?1 |
StartingWith |
findByFirstnameStartingWith |
… where x.firstname like ?1
(parameter bound with appended %) |
EndingWith |
findByFirstnameEndingWith |
… where x.firstname like ?1
(parameter bound with prepended %) |
Containing |
findByFirstnameContaining |
… where x.firstname like ?1
(parameter bound wrapped in %) |
OrderBy |
findByAgeOrderByLastnameDesc |
… where x.age = ?1 order by x.lastname desc |
Not |
findByLastnameNot |
… where x.lastname <> ?1 |
In |
findByAgeIn(Collection<Age> ages) |
… where x.age in ?1 |
NotIn |
findByAgeNotIn(Collection<Age> ages) |
… where x.age not in ?1 |
True |
findByActiveTrue() |
… where x.active = true |
False |
findByActiveFalse() |
… where x.active = false |
IgnoreCase |
findByFirstnameIgnoreCase |
… where UPPER(x.firstname) = UPPER(?1) |
实现:
1.Repository
1 | package com.nicccce.repositories; |
2.测试代码
1 | package com.nicccce; |
动态查询
Query by Example
只支持查询(可读性不好)
- 不支持嵌套或分组的属性约束,如 firstname = ?0 or (firstname = ?1 and lastname = ?2).
- 只支持字符串 start/contains/ends/regex 匹配和其他属性类型的精确匹配。
实现
1.将Repository继承QueryByExampleExecutor
1 | public interface CustomerQBERepository extends PagingAndSortingRepository<Customer,Long>, QueryByExampleExecutor<Customer> { |
2.测试代码
1 | package com.nicccce; |
Specifications
使用Query by Example只能针对字符串进行条件设置,那如果希望对所有类型支持,可以使用Specifications
实现
1 | package com.nicccce.repositories; |
1 | package com.nicccce; |
Querydsl
QueryDSL是基于ORM框架或SQL平台上的一个通用查询框架。借助QueryDSL可以在任何支持的ORM框架或SQL平台上以通用API方式构建查询。
JPA是QueryDSL的主要集成技术,是JPQL和Criteria查询的代替方法。目前QueryDSL支持的平台包括JPA,JDO,SQL,Mongodb 等等。。。
Querydsl扩展能让我们以链式方式代码编写查询方法。该扩展需要一个接口QueryDslPredicateExecutor,它定义了很多查询方法。
接口继承QuerydslPredicateExecutor接口,就可以使用该接口提供的各种方法了
引入依赖
1 | <!--query dsl--> |
添加maven插件
这个插件是为了让程序自动生成query type(查询实体,命名方式为:"Q"+对应实体名)。
添加在pom中,执行mvn compile(见前前文maven生命周期),然后在Files->Project Structure中将target中生成的generated-sources/queries文件夹从Excluded改成Sources即可。
1 | <!--该插件可以生成querysdl需要的查询对象,执行mvn compile即可(见前前文maven生命周期)--> |
实现
1 | package com.nicccce.repositories; |
- 等于 EQ : equal
.eq - 不等于 NE : not equal
.ne - 小于 LT : less than
.lt - 大于 GT : greater than
.gt - 小于等于 LE : less than or equal
.loe - 大于等于 GE : greater than or equal
.goe
1 | package com.nicccce; |
多表查询
Spring Data JPA 本身对于多表关联的操作没有扩展,我们用的都是hibernate实现的操作和注解,详情可以参阅hibernate关于Associations的官方文档
一对一
创建Account表与Customer关联
1 | /*** |
Customer表添加外键
1 |
|
cascade设置关联操作- ALL 所有持久化操作(比如删除的话,会同时删除Account表内容)
- PERSIST 只有插入才会执行关联操作
- MERGE 只有修改才会执行关联操作
- REMOVE 只有删除才会执行关联操作
fetch设置是否懒加载- EAGER 立即加载(默认)
- LAZY 懒加载( 直到用到对象才会进行查询,因为不是所有的关联对象
都需要用到,这样可以提高效率)
- 懒加载时,方法前需要加入
@Transactional(readOnly = True)注解配置事务, - 因为当通过repository调用完查询方法,session就会立即关闭, 一旦session你就不能查询,
- 加了事务后, 就能让session直到事务方法执行完毕后才会关闭。
- 懒加载时,方法前需要加入
orphanRemoval关联移除(通常在修改的时候会用到)- 一旦把关联的数据设置null ,或者修改为其他的关联数据, 如果想删除关联数据, 就可以设置为true
optional限制关联的对象不能为null- true 可以为null(默认)
- false 不能为null
mappedBy将外键约束执行另一方维护(否则双方同时加了外键依赖后,要删除时一个都删不掉)删除Customer时,会把Account的外键值设置成null
(通常在双向关联关系中,会放弃一方的外键约束)
值 = 另一方关联属性名
1
2
3
4
5
6
7
8
9
10
11
12
13
14//传入设置双向关系后的数据
public void testC(){
// 初始化数据
Account account = new Account();
account.setUsername("xushu");
Customer customer = new Customer();
customer.setCustName("丁真");
customer.setAccount(account);
account.setCustomer(customer);
repository.save(customer);
}
一对多
Spring Data JPA OneToMany级联,多方删除修改新增详解
创建Message类
1 |
|
在Customer类中设置关联关系:
1 | // fetch 默认是懒加载的,提高查询性能 |
操作:
1 | public class OneToManyTest { |
多对一
在Message类中设置关联关系:
1 | // 多对一 |
操作:
1 | public class ManyToOneTest { |
多对多
Spring-Data-JPA 定义实体类关系:多对多(增删改查)_jpa 多对多 中间实体更新操作
创建Role类
1 |
|
在Customer中设置关系
1 | // 单向多对多 |
操作
插入
如果保存的关联数据 希望使用已有的 ,就需要从数据库中查出来(为持久状态)。不能通过设置id的方式来获取,否则会提示游离状态不能持久化
如果一个业务方法有多个持久化操作, 记得加上
@Transactional,否则不能共用一个session,导致查出来的又变回游离状态在单元测试中用到了
@Transactional, 如果有增删改的操作一定要加@Commit单元测试会认为你的事务方法
@Transactional, 只是测试而已, 它不会为你提交事务, 需要单独加上@Commit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 保存
public void testC() {
List<Role> roles=new ArrayList<>();
roles.add(roleRepository.findById(9L).get());
roles.add(roleRepository.findById(10L).get());
Customer customer = new Customer();
customer.setCustName("诸葛");
customer.setRoles(roles);
repository.save(customer);
}查询
- 注意是懒加载,需要设置事务
1
2
3
4
5
public void testR() {
System.out.println(repository.findById(1L));
}删除
- 注意加上
@Transactional,@Commit。 - 多对多其实不适合删除, 因为经常出现数据出现可能除了和当前这端关联还会关联另一端,此时删除就会: ConstraintViolationException。
- 要删除, 要保证没有额外其他另一端数据关联,或者先把关系给删除。
1
2
3
4
5
6
7
8
9
10
11//删除
public void testD() {
Optional<Customer> customer = repository.findById(14L);
repository.delete(customer.get());
}- 注意加上
乐观锁
属于hibernate的功能,用于防并发修改
在实体类里加入一行
1 | private Long version; |
通过对比版本号,放置并发修改导致的错乱
审计
一般设置数据库会设置数据的创建时间、修改时间等字段,在插入和修改时设置,作为日志来记录,相对比较繁琐。
而Spring Data JPA能够帮助实现这个功能,叫做审计功能
实现
首先申明实体类,需要在类上加上注解@EntityListeners(AuditingEntityListener.class),其次在application启动类中加上注解EnableJpaAuditing,同时在需要的字段上加上@CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy等注解。
这个时候,在jpa.save方法被调用的时候,时间字段会自动设置并插入数据库,但是CreatedBy和LastModifiedBy并没有赋值,因为需要
实现AuditorAware接口来返回你需要插入的值。
1.编写AuditorAware
1 | /** |
2.在实体类中声明@EntityListeners和相应的注解
考虑到所有实体都需要声明,就写在BaseEntityModel 中
1 |
|
3.在Application 中启用审计@EnableJpaAuditing
1 |
- 本文作者: NICK
- 本文链接: https://nicccce.github.io/TechNotes/JPA-Note/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!