
我的后端笔记全集
JAVA·醉翁之意不在酒
0.java
1.HelloWorld.java
1 | public class HelloWorld { //创建类 “HelloWorld”需要与文件名一致 |
使用cmd运行:(需要在该文件目录中)
1 | $ javac HelloWorld.java |
2.变量
1 | int a, b, c; // 声明三个int型整数:a、 b、c |
命名规则:
只能包含 大小写字母、数字、下划线 和 $ ,且不能由数字开头。
保留字不等于关键字,保留字中的const,goto都不是关键字,是java保留以供后续版本使用的
基本数据类型(八种)
整数类型
| 整型 | 占用字节空间大小 | 取值范围 | 默认值 |
|---|---|---|---|
| byte | 1字节 | \([-128 , 127]\) | 0 |
| short | 2字节 | \([-32768 , 32767]\) | 0 |
| int | 4字节 | $[-2^{31} , 2^{31} - 1 ] $ \(\approx 2\times{10}^9\) | 0 |
| long | 8字节 | \([-2^{63} , 2^{63} - 1]\) \(\approx 9\times{10}^{18}\) | 0L |
浮点类型(小数)
float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
| 浮点型 | 符号位(S) | 指数位(E) | 尾数位(M) |
|---|---|---|---|
| float | 1bit | 8bit | 23bit |
| double | 1bit | 11bit | 52bit |
| 浮点型 | 占用字节空间大小 | 取值范围 | 默认值 |
|---|---|---|---|
| float | 4字节 | \(2^{23} = 8388608\) | 0.0F |
| double | 8字节 | \(2^{52} = 4503599627370496\) | 0.0 |
字符类型
| 字符型 | 占用字节空间大小 | 取值范围 | 默认值 |
|---|---|---|---|
| char | 2字节 | 0 ~ 65535 | ‘’ |
布尔类型
| 布尔型 | 占用字节空间大小 | 取值范围 | 默认值 |
|---|---|---|---|
| boolean | 视情况而定 | true、false | false |
数据类型转换
转化从低级到高级:byte,short,char(三者同级,不能自动转换)—> int —> long—> float —> double
低级转换高级:自动类型转换
高级转换低级:强制类型转换
1 | public class Demo { |
数据类型赋值
1 | //可以将低精度赋值给高精度 |
关于输入数字赋值的处理
当在java代码中输入一串数字时,编译器会判断一下是否在相应类型的范围内,若在,则
1 | long l = 10000000000; //整数过大 |
3.输入输出
1 | public class Main { |
next 和 nextLine 区别
| next | nextLine |
|---|---|
| 不能读入含有空格的字符串,以空格、Table、回车作为本次输入的结束符 | 可以读入空格.以回车作为结束符 |
| 不会读取回车作为它的值 | 会读取回车作为它的值 |
也就是说next不会消耗后面的空白符,只会跳过前面的空白符
4.循环结构
跟c++不能说是一模一样,只能说是没有区别
for
1 | for(int i = 0; i < 10; i++){ |
while
1 | int i = 0; |
do while
1 | int i = 0; |
5.分支结构
跟c++不能说是没有区别,只能说是一模一样
if
1 | public class Main { |
swich
1 | char grade = 'C'; |
输出 :
2
你的等级是 C
假如没有break,则会输出符合条件的以下的所有case,直到出现break
1 | public class Test { |
输出:
2
3
2
default
6.数组
创建数组
数组是一种对象(但是在cpp里似乎属于变量)
以下是建议使用的方法
1 | public class TestArray { |
如果创建一个类的数组,但没有为数组中的元素赋值,那么这些元素的值将是该类的默认值。对于引用类型(如对象),默认值为null。对于基本类型(如int,
double等),它们的默认值是0(对于整数类型)或0.0(对于浮点类型)。
数组可以直接通过赋值创建:
1 | int[] b = {1,2,3}; |
实际上这里是编译器自己补上了缺失的内容,经过反编译后如下:
1 | int[] b = new int[]{1, 2, 3}; |
所以如果想先创建再赋值,不能缺失new的过程
1 | int[] b ; |
二维数组的初始化
必须要设定第一个框里的值(行数)
1 | static int[][] a = new int [10][]; |
二维数组实际上只是一个包含int[]类型的一位数组,所以说他的元素可以通过如下方式进行覆盖的,index不需要全部一样。
1 | public static void main(String[] args) { |
遍历数组
1 | // 打印所有数组元素 |
For-Each 循环
JDK 1.5 引进了一种新的循环类型,被称为 For-Each 循环或者加强型循环,它能在不使用下标的情况下遍历数组。语法格式如下:
1 | // 打印所有数组元素 |
7.Math 类
1 | //三角函数全用弧度制 |
| 方法 | 含义 |
|---|---|
n.???Value() |
将 Number 对象转换为xxx数据类型的值并返回(数字间的相互转换) |
n.compareTo(m) |
将number对象与参数比较,n>m返回1,n<m返回-1,n=m返回0 |
n.toString() |
变成字符串 |
Math.abs(n) |
绝对值 |
Math.ceil(n) |
向上取整,返回类型为double |
Math.floor(n) |
向下取整,返回类型为double |
Math.rint(n) |
四舍六入五成双 |
Math.round(n) |
四舍五入,等价于Math.floor(x+0.5) |
Math.min(n,m)Math.max(n,m) |
略 |
Math.exp(n) |
\(e^n\) |
Math.log(n) |
\(ln(n)\) |
Math.pow(n,m) |
\(n^m\) |
Math.sqrt |
平方根 |
Math.random() |
\([0,1)\)随机数 |
8.Character 类
| 方法 | 含义 |
|---|---|
Character.isLetter(ch) |
是否是个字母(返回bool) |
Character.isDigit(ch) |
是否是个数字字符(返回bool) |
Character.toUpperCase(ch) |
转大写 |
Character.toLowerCase(ch) |
转小写 |
Character.toString(ch) |
返回字符的字符串形式,字符串的长度仅为1 |
9.BigInteger
Java中BigInteger类的使用方法详解,常用最全系列!-CSDN博客
读入方法
nextBigInteger():控制台读入一个BigInteger型数据,类似于int型的nextInt()
1 | public void test() { |
构造方法
默认为十进制,同时也支持自定义进制类型(已存在的)
1 | public void testScale() { |
基本运算
返回值为BigInteger类型:add(),subtract(),multiply(),divide(),mod(),remainder(),pow(),abs(),negate()
1 | public void testBasic() { |
比较大小
compareTo()返回一个int型数据:大于->1
等于->0 小于->-1
max(),min():分别返回大的(小的)那个BigInteger数据
1 | public void testCompare() { |
常量
ZERO,ONE,TEN
返回值为BigInteger类型
1 | public void testFinalNum() { |
类型转换
将BigInteger数据转换成基本数据类型,还可以转换成radix进制的字符串形式
1 | public void testToAnother() { |
二进制运算(左移右移)
返回值为BigInteger类型,此类方法不常用,有备无患
1 | public void testBinaryOperation() { |
权限控制
setBit(),testBit():可用于菜单的权限控制,非常好用,原理如下:
1 | public void testSetAndTest() { |
构造方法没有任何返回类型,甚至没有void返回类型
10.继承(Inheritance)
可见性修饰符
public可以在类、方法、数据源前使用public修饰符,表示他们可以被任何其他类访问。protected仅允许子类访问父类中的数据域或方法,同一个包中也可以访问。对于类,只能修饰内部类
默认修饰符(
default) 默认类、方法和数据域仅可以被同一个包中的任何一个类访问。这称为包私有(package-private)或包内访问(package-access)。private限定方法和数据域只能在自己的类中访问。注意修饰符private只能应用在类成员上,修饰符public可以应用在类或类成员上。在局部变量上使用public和private都会导致编译错误。对于类,只能修饰内部类
- 在大多数情况下构造方法都是公共的,但如果想防止用户创建类的实例,就使用私有构造方法,实例化时会提示构造方法不可视错误。例如Math类所有方法都是静态方法,所以为防止用户创建Math对象,其构造方法定义如下
1
2
3private Math(){
}
| 类中成员修饰符 | 同一类中可访问 | 同一包中可访问 | 在子类中可访问 | 在不同包中可访问 |
|---|---|---|---|---|
public |
√ | √ | √ | √ |
protected |
√ | √ | √ | - |
(default) |
√ | √ | - | - |
private |
√ | - | - | - |
- 数据、方法的访问权限 不能突破类的访问权限
- 子类可以扩大父类定义的作用范围,但是不能削弱父类的作用范围
@Override
在Java中,@Override注解是一个元注解,它用于指示一个方法应该重写父类中的方法。使用@Override注解可以帮助编译器检查代码的正确性,确保方法签名与父类中的方法签名匹配。
当你在子类中使用@Override注解时,编译器会检查以下几点:
- 子类中的方法是否与父类中的方法具有相同的名称、参数列表和返回类型。
- 子类中的方法是否是父类中的方法的子类型。
- 子类中的方法是否具有与父类中要重写的方法相同(或大于)的访问级别(例如,都是public)。
如果满足上述条件,编译器将允许该方法重写父类中的方法。如果子类中的方法不满足这些条件,编译器将报错。
使用@Override注解的好处是:
- 提高代码的可读性:通过在方法声明前添加
@Override注解,可以清楚地表明该方法是重写父类中的方法。这有助于其他开发人员理解代码的结构和意图。 - 减少错误:编译器会检查代码的正确性,确保方法签名与父类中的方法签名匹配。这有助于避免因拼写错误或参数列表不匹配而无意间重写方法的情况。
- 增强代码的可维护性:如果父类中的方法签名发生变化,编译器将提示错误,从而及早发现并修复问题。这有助于保持代码的健壮性和可维护性。
总之,@Override注解在Java中用于指示一个方法是重写父类中的方法,它有助于提高代码的可读性、减少错误并增强代码的可维护性。
示范代码
1 | package Book; |
1 | package Book; |
1 | package Book; |
super引用
super()调用必须是(所有)构造函数主体中的第一条语句。- 当父类中有无参构造方法时(包括默认的),子类的构造方法可以自动调用
- 当父类不含无参构造方法时,子类必须要用
super调用父类构造方法
- 无法使用super.super调用祖父类成员
方法重写(Overriding Methods)
子类方法访问权限不低于被覆盖的父类方法。
如果父类中的一个方法不希望被覆盖,用final修饰它:
1
public final void setPages(int numPages) {}
对象的真实类型决定方法调用的类型,子类对象调用子类版本,父类对象调用父类版本。
(调用哪一个版本,取决对象new的类型,而非对象引用类型)
且当引用类型为对象的父类时,不能调用子类中独有的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static void main(String[] args) {
Dictionary dictionary = new Dictionary(1,100);
dictionary.setSuperDefinitions(101);
System.out.println(dictionary.definitions); //100
System.out.println(((Book)dictionary).definitions); //Book类中被覆盖的definitions:101
((Book)dictionary).setDefinitions(102); //这里只调用了Dictionary的setDefinitions方法
System.out.println(dictionary.definitions); //102
System.out.println(((Book)dictionary).definitions); //Book类中被覆盖的definitions:101
Book dictionary2 = new Dictionary(1,101);
dictionary2.setDefinitions(103); //这里也调用了Dictionary的setDefinitions
System.out.println(dictionary2.definitions); //Book类中被覆盖的definitions:0
System.out.println(((Dictionary)dictionary2).definitions); //Dictionary类中的definitions:103
}重写的方法要求形参相同,返回值相同或者为父类方法的返回值的子类。
(java编译器去检测时,先去看方法名是否相同,然后再去比较参数列表,如果不同就认为是重载,相同就判断是Override,随后再去判断返回值类型,不符合要求就遍历失败)
1 | //示例题目 |
- 子类无法直接访问父类的private成员,但是可以通过调用父类能访问该成员的方法来间接访问。
- 子类可以重写祖父类的方法。
- Two children of the same parent are called siblings.
标准覆盖的toString以及equals方法头
1 | class MyClass{ |
静态方法的覆盖
java静态方法不能重写,但是允许覆盖,要求是形参相同(否则也只认定为重载),返回值也必须相同或为父类返回值的子类(这就很奇怪了)
假如通过对象调用静态方法,看的是对象的引用类型而非对象new的类型。
1 | public static void main(String[] args) { |
影子变量(Shadowing Vriables)
java中子类可以定义与父类同名的变量(虽然不提倡这么做),变量类型、是否静态、可见性修饰符毫无要求,便成为影子变量。
影子变量对于父类的变量仅仅是覆盖关系,即父类和子类中是两个不同的变量,只不过在子类中优先调用了这个影子变量,可以通过super或者强转的方式调用。
同名变量的调用版本也取决于引用类型。
1 | public static void main(String[] args) { |
抽象类(Abstract Classes)
定义抽象方法:
1
public abstract void setDefinitions(int numDefinitions);
抽象方法需要不允许设置为
private,尽量设置为public或者protected。抽象类的子类必须覆盖父类的抽象方法,否则它也将是抽象的。
抽象方法不能定义为最终方法或静态方法。
抽象类的使用是软件设计的一个重要元素,它允许我们在层次结构中建立公共元素,这些元素过于笼统,无法实例化。
抽象类不必一定包含抽象方法。
抽象类在类层次结构中充当占位符。即一个抽象类代表一个抽象体,本身并没有足够的定义使其成为可用类。(在UML类图(类层次结构)中,抽象类的类名用斜体表示)
与抽象类有关的变量,方法调用遵循正常类
1
2
3
4
5
6
7
8Media book1 = new Book(1);
book1.setDefinitions(100);
System.out.println(book1.definitions); //100
Media dictionary3 = new Dictionary(1,100);
((Book)dictionary3).setDefinitions(101);
System.out.println(((Dictionary)dictionary3).definitions); //Dictionary类中被覆盖的definitions:101
System.out.println(dictionary3.definitions); //Book类中继承Media的被覆盖的definitions:0
System.out.println(((Media)dictionary3).definitions); //Media类中被覆盖的definitions:0当抽象类中重写了一个其父类有的方法并将其抽象化时,便将其抽象化了,子类要求重写该方法。
11.接口(Interfaces)
基础操作
1 | package Test; |
1 | import Test.Doable; |
1 | package Book; |
Java接口是抽象方法和常量
final的集合。出现非final的变量会破坏接口的抽象性和不变性。接口中的抽象类访问权限必须是
public,可以省略,但习惯不省略,abstract可以被省略。接口可以继承其他接口,也只能继承接口。
1
interface I3 extends I1, I2 {}
implements和extends的书写顺序并没有严格的要求。但是,按照一般的编码规范,通常将implements放在extends之前。JDK1.8 以后,接口可以有
default方法或static方法(不能同时修饰),被称为默认方法和静态方法,都是public的可见度,允许包含方法的实现,主要原因是为了增加代码的可读性和灵活性。通过允许接口包含实现和工具方法,我们可以将相关的行为组织在一个地方,而不是将它们分散在多个类中。- 但是
static方法为了避免多实现带来的歧义,只能通过具体的接口名调用。在接口继承接口的情况下也无法将父接口的static方法继承过来。
1
2
3
4
5
6
7
8public static void main(String[] args) {
CanDo dog = new CanDo();
Doable cat = new CanDo();
Doable.printTest(); //1
/*cat.printTest(); //错误:只能在包含接口类时调用static方法
dog.printTest(); //错误:只能在包含接口类时调用static方法
CanDo.printTest()*/ //错误:只能在包含接口类时调用static方法
}其中,
default修饰的方法是可以被Override的,并且是遵循new的类型(即对这些继承的处理等同于抽象类)。1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args) {
CanDo dog = new CanDo();
Doable cat = new CanDo();
Doable.printTest(); //1
System.out.println(dog.say()); //miaomiao
System.out.println(cat.say()); //miaomiao
CanDo dogs = new VeryCanDo();
Doable dogss = new VeryCanDo();
VeryCanDo dogsss = new VeryCanDo(); //wangwang
System.out.println(dogs.say()); //wangwang
System.out.println(dogss.say()); //wangwang
System.out.println(dogsss.say()); //wangwang
}想要在其他子类调用这个
static方法只能在父类去写一个,然后遵前文的各种规则。1
2
3
4
5
6//在CanDo中补一个这个方法
public class CanDo implements Doable {
static void printTest(){ //也就是说在父类去写一个同样的方法
System.out.println("2");
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14public static void main(String[] args) {
CanDo.printTest(); //2
VeryCanDo.printTest(); //2
CanDo dog = new CanDo();
Doable cat = new CanDo();
Doable dogs = new VeryCanDo();
CanDo dogss = new VeryCanDo();
VeryCanDo dogsss = new VeryCanDo();
/*cat.printTest(); //错误:只能在包含接口类时调用static方法*/
dog.printTest(); //2
/*dogs.printTest(); //错误:只能在包含接口类时调用static方法*/
dogss.printTest(); //2
dogsss.printTest(); //2
}- 但是
如果一个类实现了两个接口,并且这两个接口中都有同名的默认方法,那么这个类必须实现这个默认方法。
super也可以运用于接口,形如Interface1.super.myMethod()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20interface Interface1 {
default void myMethod() {
System.out.println("Interface1's default method");
}
}
interface Interface2 {
default void myMethod() {
System.out.println("Interface2's default method");
}
}
class MyClass implements Interface1, Interface2 {
// 必须实现两个接口中的myMethod方法
public void myMethod() {
Interface1.super.myMethod(); // 调用Interface1中的myMethod
Interface2.super.myMethod(); // 调用Interface2中的myMethod
}
}
接口直接创建类
1 | interface I1{ |
1 | public static void main(String[] args) { |
在这里,直接用接口创建对象,实际上是写了一个实现了该接口的匿名类,在编译文件中可以发现多了Test$1.class,Test$2.class两个字节码文件
因此,虽然接口中有toString的抽象方法,但是由于匿名类默认继承了Object,这个抽象方法被Object中的toString实现了,固无需再次实现
Comparable
Comparable位于java.lang包中。这个接口主要用于对对象进行排序。当你希望一个类能够被排序时,通常会实现这个接口。Comparable接口只有一个抽象方法:compareTo,参数是一个对象,返回一个整型值。这个方法用于比较当前对象与另一个对象的大小。1
2
3public interface Comparable<T>{
int compareTo(T o); // 泛型
}为了使类能够自然排序,通常会按照某种属性或关系来定义
compareTo方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 其他属性和方法...
public int compareTo(Person other) {
return this.age - other.age; // 比较年龄
}
}使用
Comparable接口的好处是,你可以使用 Java 的内建排序方法(如Collections.sort()或数组的Arrays.sort())来对实现这个接口的对象列表或数组进行排序,而不需要额外的比较器(Comparator)。这使得代码更加简洁和易于维护。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.util.Arrays;
import java.util.List;
public class SortingExample {
public static void main(String[] args) {
Person[] persons = new Person[]{
new Person("Alice", 25),
new Person("Bob", 30),
new Person("Charlie", 20)
};
Arrays.sort(persons); // 使用默认的排序方式(按年龄升序)
for (Person person : persons) {
System.out.println(person.getName() + " " + person.getAge());
}
}
}使用
Comparator:也可以创建一个Comparator并传递给Arrays.sort()方法:当
compare方法返回负数、零或正数时,Arrays.sort()会相应地认为第一个元素小于、等于或大于第二个元素。如果compare方法返回正数,它意味着你告诉Arrays.sort()方法:"第一个元素应该排在第二个元素之前",从而导致这两个元素的位置交换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
public class SortingExample {
public static void main(String[] args) {
Person[] persons = new Person[]{
new Person("Alice", 25),
new Person("Bob", 30),
new Person("Charlie", 20)
};
Arrays.sort(persons, new Comparator<Person>() { // 使用自定义的排序方式(按姓名升序)
public int compare(Person p1, Person p2) {
return p1.getName().compareTo(p2.getName()); // 按姓名升序排序
}
});
for (Person person : persons) {
System.out.println(person.getName() + " " + person.getAge());
}
}
}
12.多态性
- 在继承和接口两章已经讨论得差不多了,这里总结一下:
- 对于实例方法,永远调用的是对象本身的版本,而引用类型只是为了保证有这个方法。
- 当出现同名的类方法或者变量,看的都是引用类型。
- 接口里的
static方法无法通过子类的类名来调用。
- 小讨论
- 可以这么理解:
- 当一个对象的方法发生重写时,他的父类中的方法都会链接至那个重写的方法。
- 调用一个对象的方法时还是会去看这个引用类型所对应的方法,只不过会调用到那个被重写的最新方法去罢了。
- 对于方法调用方法的情况,都是会去调用所在类中的方法,遇到重写时就会跳到最新的重写的那个类。
- 对于静态变量和变量、常量,也是遵循这个原则,调用方法所在类或者该引用类型所指类中的成员,只不过就没有跳转之类的花里胡哨了。
- 可以这么理解:
1 | package Test; |
1 | package Test2; |
1 | package Test2; |
下面给出这两个方法反编译过后的样子,便于理解:
1 | // |
1 | // |
关于继承的实验
- 这个例子里父类能调用或者重写祖父类,子类不行。
1
2
3
4
5
6
7
8
9
10
11
12package Test2;
public class B { //祖父类
public B(){
count++;
System.out.println("构造 B:" + count);
}
int h(){ //包访问权限,只有父类可见,子类不可见
System.out.println("调用了B.h()");
return 0;
}
}1
2
3
4
5
6
7
8
9
10
11
12package Test2;
public class A extends B { //父类
public A(int x){
System.out.println("构造 A: " + x);
}
public int i(){
System.out.println("调用了A.i()");
h();
return 0;
}
}1
2
3
4
5
6
7
8
9package Test;
import Test2.A;
public class C extends A{ //子类
public C(int x){
super(x);
}
}1
2
3
4
5
6
7
8
9
10public static void main(String[] args) {
C c = new C(666);
c.i();
}
\*
构造 B:1
构造 A: 666
调用了A.i()
调用了B.h()
*/
能不转就不转
对于直接使用数字,但是符合多个重载的方法的情况时,如输入g( int ),但是同时有g( long ),g( double ),遵循能不自动转换就不自动转换的原则。
会优先转为int,其次是long,然后float,最后考虑double
1 | package Test2; |
1 | package Test2; |
1 | public class Test { |
1 | 构造 B:1 |
13.异常
(1)try-catch-finally语句
执行顺序
在Java的try-catch语法中,如果try块中的代码抛出了异常,那么控制权将立即转移到与该异常匹配的catch块。这意味着,一旦异常被抛出,try块中剩余的代码将不会被执行。
例如:
1 | try { |
在这个例子中,10 / 0会抛出一个ArithmeticException,所以System.out.println("Try block: Result is " + result);这行代码将不会被执行。但是,System.out.println("This will always be printed, regardless of whether an exception is thrown in the try block.");这行代码会在try-catch块之后执行,无论try块中是否抛出了异常。
finally运行条件
在Java的try-catch-finally语句中,finally块是一个可选的部分,它总是在try和catch块之后执行,无论是否发生了异常。也就是说,无论try块中的代码是否成功执行,或者是否抛出了异常,finally块中的代码都会执行。
(无论try或catch块中的代码是否返回)
1 | public void myMethod() { |
假如在finally中也有return,那么返回值将被覆盖。
这种设计使得finally块非常适合执行一些清理工作,比如关闭打开的文件、释放数据库连接等。无论是否发生异常,这些清理工作都应该被执行,以确保资源的正确释放。
下面是一个简单的例子:
1 | public void myMethod() { |
(2)异常种类
1 | graph LR |
非受检异常:程序员可以直接使用throw语句抛出异常,而不需要在方法签名中使用throws关键字进行声明。这是因为编译器认为这些异常是可预见的,并且程序员应该负责在代码中适当地处理它们。
受检型异常:一种需要被显式处理的异常,需要在方法签名中使用throws关键字进行声明,以便告知调用者该方法可能会抛出异常,并要求调用者处理或继续抛出该异常。
IOException
IOException是Java中表示输入/输出异常的类。当进行输入/输出操作时,可能会发生各种异常,其中许多都属于IOException。以下是一些属于IOException的错误:
文件未找到异常(FileNotFoundException):当尝试打开不存在的文件时,会抛出此异常。
文件已存在异常(FileAlreadyExistsException):当尝试创建已存在的文件或目录时,会抛出此异常。
文件锁定异常(FileLockedException):当尝试对文件进行锁定操作时,如果文件已被其他进程锁定,则会抛出此异常。
非法参数异常(IllegalArgumentException):当输入参数不合法时,可能会抛出此异常。例如,当使用FileWriter构造函数时,如果传递给构造函数的字符编码无效,则会抛出此异常。
非法状态异常(IllegalStateException):当对象处于不适当的状态进行操作时,可能会抛出此异常。例如,当使用BufferedReader的readLine()方法读取已关闭的流时,会抛出此异常。
对象被破坏异常(ObjectInputValidationException):当尝试从反序列化对象时,如果输入流包含无效或损坏的对象数据,则会抛出此异常。
除了上述异常之外,IOException还包含其他与输入/输出操作相关的异常,例如读写超时、EOFException等。
(3)自定义异常
- 自定义异常作为内部类:
1 | public class MyService { |
将自定义异常作为内部类时,通常会使用public和static修饰符.
public修饰符:- 确保异常类可以从外部访问:由于异常类是定义在另一个类中的,如果不使用
public修饰符,外部类将无法直接访问它。通过将异常类声明为public,我们确保了其他类可以访问并使用它。
- 确保异常类可以从外部访问:由于异常类是定义在另一个类中的,如果不使用
static修饰符:- 便于引用和使用:当一个内部类被声明为
static时,它可以作为顶层类来使用,而不需要外部类的名称。
- 便于引用和使用:当一个内部类被声明为
在其他类或包中,可以通过以下方式引用和使用这个自定义异常:
1 | import com.example.MyService.ServiceException; // 假设MyService位于com.example包中 |
- 自定义异常作为单独外部类:
1 | public class MyCustomException extends Exception { |
由于它是单独的外部类,其他类也可以直接通过MyCustomException来引用和使用。
13.Collection
Collection Interfaces:
作集合的通用方法,包括添加、删除、遍历、查找等各个子类都需要实现
add(E e):将元素e添加到集合中
remove(Object o): 从集合中删除对象o
contains(Object o): 判断集合中是否包含对象o
size():返回集合中元素的个数
iterator(): 返回集合中元素的迭代器
1 | graph LR |
Collections
Java集合框架提供的操作Set、List和Map等Collection的工具类
该类提供了一系列的静态方法,可以实现对集合进行排序、查找、替换、复制等操作
排序方法: sort、reverse、
shuffle、swap、rotate
查找方法: binarySearch
替换方法: replaceAll、fill
复制方法:copy
同步方法:
synchronizedCollection、synchronizedList、
synchronizedMap等
不可修改方法:
unmodifiableCollection、unmodifiableList、unmodifiableMap等
其他方法:
frequency、maxmin、disjoint、frequency、indexOfSubList、lastlndexOfSubList等
LinkList(链表)
总的来说,就是每一个链表的节点ListNode都是包含了data和next两个元素
其中next元素就是指向他的下个节点的位置
1 | public class ListNode<E>{ |
1 | class LinkedList<E>{ |
基本操作
1 | //=====遍历===== |
定位的基础上插入、删除
1 | //=====定位target===== |
前端基础
## 1.前端开发介绍
那在讲解web前端开发之前,我们先需要对web前端开发有一个整体的认知。主要明确一下三个问题:
1). 网页有哪些部分组成 ?
文字、图片、音频、视频、超链接、表格等等。
2). 我们看到的网页,背后的本质是什么 ?
程序员写的前端代码 (备注:在前后端分离的开发模式中,)
3). 前端的代码是如何转换成用户眼中的网页的 ?
通过浏览器转化(解析和渲染)成用户看到的网页
浏览器中对代码进行解析和渲染的部分,称为 浏览器内核
而市面上的浏览器非常多,比如:IE、火狐Firefox、苹果safari、欧朋、谷歌Chrome、QQ浏览器、360浏览器等等。 而且我们电脑上安装的浏览器可能都不止一个,有很多。
但是呢,需要大家注意的是,不同的浏览器,内核不同,对于相同的前端代码解析的效果也会存在差异。 那这就会造成一个问题,同一段前端程序,不同浏览器展示出来的效果是不一样的,这个用户体验就很差了。而我们想达到的效果则是,即使用户使用的是不同的浏览器,解析同一段前端代码,最终展示出来的效果都是相同的。
要想达成这样一个目标,我们就需要定义一个统一的标准,然后让各大浏览器厂商都参照这个标准来实现即可。 而这套标准呢,其实早都已经定义好了,那就是我们接下来,要介绍的web标准。
Web标准也称为网页标准,由一系列的标准组成,大部分由W3C( World Wide Web Consortium,万维网联盟)负责制定。由三个组成部分:
- HTML: HyperText Markup Language,超文本标记语言。
超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。
标记语言:由标签构成的语言
- HTML标签都是预定义好的。例如:使用
标签展示标题,使用展示超链接,使用
展示图片,
- HTML代码直接在浏览器中运行,HTML标签由浏览器解析。
- HTML标签都是预定义好的。例如:使用
- CSS:Cascading Style Sheet,层叠样式表,负责网页的表现(页面元素的外观、位置等页面样式,如:颜色、大小等)。
- JavaScript:负责网页的行为(交互效果)。
当然了,随着技术的发展,我们为了更加快速的开发,现在也出现了很多前端开发的高级技术。例如:vue、elementui、Axios等等。
2.HTML-CSS基础语法
- 示例代码
1 | <!-- 文档类型为html --> |
html基本结构
html有固定的基本结构
1 | <html> |
其中<html>是根标签,<head>和<body>是子标签,<head>中的字标签<title>是用来定义网页的标题的,里面定义的内容会显示在浏览器网页的标题位置。
而 <body> 中编写的内容,就网页中显示的核心内容。
图片
图片标签:
<img>常见属性:
src:指定图像的url (可以指定 绝对路径 , 也可以指定 相对路径)width:图像的宽度 (像素 / 百分比 , 相对于父元素(示例中,父元素指的是body)的百分比)height:图像的高度 (像素 / 百分比 , 相对于父元素的百分比)- 备注: 一般width 和 height 我们只会指定一个,另外一个会自动的等比例缩放。
路径书写方式:
绝对路径:
- 绝对磁盘路径: C:_logo.png
<img src="C:\Users\Administrator\Desktop\HTML\img\news_logo.png">
- 绝对网络路径:
https://i2.sinaimg.cn/dy/deco/2012/0613/yocc20120613img01/news_logo.png
<img src="https://i2.sinaimg.cn/dy/deco/2012/0613/yocc20120613img01/news_logo.png">
- 绝对磁盘路径: C:_logo.png
相对路径:
- ./ : 当前目录 , 可以省略的
./img/news_logo.png或img/news_logo.png
- ../: 上一级目录,不可省略
- ./ : 当前目录 , 可以省略的
<span>标签:没有语义的布局标签,一行可以显示多个(组合行内元素),宽度和高度默认由内容展开。
CSS引入标题样式
| 名称 | 语法描述 | 示例 |
|---|---|---|
| 行内样式 | 在标签内使用style属性,属性值是css属性键值对 | <h1 style="属性名:属性值;">中国新闻网</h1> |
| 内嵌样式 | 在head中定义<style>标签,在标签内部定义css样式 |
<style> h1 {...} </style> |
| 外联样式 | 在head中定义<link>标签,通过href属性引入外部css文件 |
<link rel="stylesheet" href="css/news.css"> |
对于上述3种引入方式,企业开发的使用情况如下:
- 内联样式会出现大量的代码冗余,不方便后期的维护,所以不常用。
- 内部样式,通过定义css选择器,让样式作用于当前页面的指定的标签上。
- 外部样式,html和css实现了完全的分离,企业开发常用方式。
颜色表示
表示方式 表示含义 取值 关键字 预定义的颜色名 red、green、blue... rgb表示法 红绿蓝三原色,每项取值范围:0-255 rgb(0,0,0)、rgb(255,255,255)、rgb(255,0,0) 十六进制表示法 #开头,将数字转换成十六进制表示 #000000、#ff0000、#cccccc,简写:#000、#ccc
CSS选择器
选择器是选取需设置样式的元素(标签),因为我们是做后台开发的,所以对于css选择器,我们只学习最基本的3种。
选择器通用语法如下:
1 | 选择器名 { |
优先级:id选择器>类选择器>标签选择器
1.元素(标签)选择器:
- 选择器的名字必须是标签的名字
- 作用:选择器中的样式会作用于所有同名的标签上
1 | 元素名称 { |
例子如下:
1 | h1{ |
2.id选择器:
- 选择器的名字前面需要加上#
- 作用:选择器中的样式会作用于指定id的标签上,而且有且只有一个标签
- (id不可重复)
1 | #id属性值 { |
例子如下:
1 | #did { |
3.类选择器:
- 选择器的名字前面需要加上 .
- 作用:选择器中的样式会作用于所有class的属性值和该名字一样的标签上
- (class可以重复)
1 | .class属性值 { |
例子如下:
1 | .cls{ |
超链接
标签: a标签
<a href="..." target="...">央视网</a>属性:
href: 指定资源访问的urltarget: 指定在何处打开资源链接_self: 默认值,在当前页面打开_blank: 在空白页面打开
CSS属性避免默认变蓝加下划线
1
2
3
4
5
6
7<style>
a {
color: #000;
/* 指定文本装饰 */
text-decoration: none;
}
</style>
视频、音频
视频标签:
<video>```HTML
1
2
3
4
5
6
7
8
9
10
11
12
13
- 属性:
- `src`: 规定视频的url
- `controls`: 显示播放控件
- `width`: 播放器的宽度
- `height`: 播放器的高度
- 音频标签: <audio>
- ```html
<!-- 音频 -->
<audio src="audio/1.mp3" controls></audio>属性:
src: 规定音频的urlcontrols: 显示播放控件
段落
换行标签:
<br>- 注意: 在HTML页面中,我们在编辑器中通过回车实现的换行, 仅仅在文本编辑器中会看到换行效果, 浏览器是不会解析的, HTML中换行需要通过br标签
段落标签:
<p>- 如: <p> 这是一个段落 </p>
首行缩进和对齐方式
1 | p { |
文本格式
| 效果 | 标签 | 标签(强调) |
|---|---|---|
| 加粗 | b | strong |
| 倾斜 | i | em |
| 下划线 | u | ins |
| 删除线 | s | del |
前面的标签 b、i、u、s 就仅仅是实现加粗、倾斜、下划线、删除线的效果,是没有强调语义的。 而后面的strong、em、ins、del在实现加粗、倾斜、下划线、删除线的效果的同时,还带有强调语义。「在网页显示中」没有什么区别,在代码编写上有区别。
占位符
在HTML页面中无论输入了多少个空格, 最多只会显示一个。
可以使用空格占位符( ;
)来生成空格,如果需要多个空格,就使用多次占位符。
那在HTML中,除了空格占位符以外,还有一些其他的占位符,如下:
| 显示结果 | 描述 | 占位符 |
|---|---|---|
|
空格 | |
< |
小于号 | < |
> |
大于号 | > |
& |
和号 | & |
" |
引号 | " |
' |
撇号 | ' |
|
TAB |   |
盒子模型
- 盒子:页面中所有的元素(标签),都可以看做是一个 盒子,由盒子将页面中的元素包含在一个矩形区域内,通过盒子的视角更方便的进行页面布局
- 盒子模型组成:内容区域(content)、内边距区域(padding)、边框区域(border)、外边距区域(margin)
布局标签
布局标签:实际开发网页中,会大量频繁的使用 div 和 span 这两个没有语义的布局标签。
标签:
<div><span>特点:
div标签:一行只显示一个(独占一行)
宽度默认是父元素的宽度,高度默认由内容撑开
可以设置宽高(width、height)
span标签:- 一行可以显示多个,用来组合行内元素
- 宽度和高度默认由内容撑开
- 不可以设置宽高(width、height)
divCSS属性:width:设置宽度
height:设置高度
box-sizing: border-box; 指定width height为盒子的高宽,默认是content的高宽
border:设置边框的属性,如:1px solid #000 宽度 线条类型 颜色
background-color:背景色
padding:内边距 如:padding: 20px 20px 20px 20px; 分别表示 上 右 下 左 ; 边距都一样时可以简写: padding: 20px;
margin:外边距
如果只需要设置某一个方位的边框、内边距、外边距,可以在属性后面加上 -位置,如:padding-top、left、right、end
```css #center { width: 65%; /* 通过外边距设置居中 / / margin: 0% 17.5% 0% 17.5%; / margin: 0 auto;/ 上下外边距为0,浏览器自动计算左右边距 */ }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
### 表格标签
- `<table>` : 用于定义整个表格, 可以包裹多个 <tr>, 常用属性如下:
- border:规定表格边框的宽度
- width:规定表格的宽度
- cellspacing:规定单元之间的空间
- `<tr>`:表格的行,可以包裹多个 `<td>`
- `<td>` :表格单元格(普通),可以包裹内容 , 如果是表头单元格,可以替换为`<th>` (加粗)
### 表单标签
- 表单标签: `<form>`
- 表单属性:
- action: 规定表单提交时,向何处发送表单数据,表单提交的URL,默认提交到当前页面。
- method: 规定用于发送表单数据的方式,常见为: GET、POST,默认为GET。
- GET:表单数据是拼接在url后面的, 如: xxxxxxxxxxx?username=Tom&age=12,url中能携带的表单数据大小是有限制的。
- POST: 表单数据是在请求体(消息体)中携带的,大小没有限制。
- 表单项标签:
- <input>:表单项 , 通过type属性控制输入形式。
| type取值 | **描述** |
| ------------------------ | ---------------------------------------- |
| text | 默认值,定义单行的输入字段 |
| password | 定义密码字段 |
| radio | 定义单选按钮 |
| checkbox | 定义复选框 |
| file | 定义文件上传按钮 |
| date/time/datetime-local | 定义日期/时间/日期时间 |
| number | 定义数字输入框 |
| email | 定义邮件输入框,必须要有@ |
| hidden | 定义隐藏域,看不到,但是会提交 |
| submit / reset / button | 定义**提交按钮** / 重置按钮 / 可点击按钮 |
- <select>: 定义下拉列表, <option> 定义列表项
- <textarea>: 文本域
```html
<!-- value: 表单项提交的值 -->
<form action="" method="post">
姓名: <input type="text" name="name"> <br><br>
密码: <input type="password" name="password"> <br><br>
性别: <input type="radio" name="gender" value="1"> 男
<label><input type="radio" name="gender" value="2"> 女 </label>
<!-- 加<label>后点那个文字也能选中元素 --><br><br>
爱好: <label><input type="checkbox" name="hobby" value="java"> java </label>
<label><input type="checkbox" name="hobby" value="game"> game </label>
<label><input type="checkbox" name="hobby" value="sing"> sing </label> <br><br>
图像: <input type="file" name="image"> <br><br>
生日: <input type="date" name="birthday"> <br><br>
时间: <input type="time" name="time"> <br><br>
日期时间: <input type="datetime-local" name="datetime"> <br><br>
邮箱: <input type="email" name="email"> <br><br>
年龄: <input type="number" name="age"> <br><br>
学历: <select name="degree">
<option value="">----------- 请选择 -----------</option>
<option value="1">大专</option>
<option value="2">本科</option>
<option value="3">硕士</option>
<option value="4">博士</option>
</select> <br><br>
描述: <textarea name="description" cols="30" rows="10"></textarea> <br><br>
<input type="hidden" name="id" value="1">
<!-- 表单常见按钮 -->
<input type="button" value="按钮"><!-- 将会配合事件监操作 -->
<input type="reset" value="重置">
<input type="submit" value="提交">
<br>
</form>
注意:表单中的所有表单项,要想能够正常的采集数据,在提交的时候能提交到服务端,表单项必须指定name属性。
3.JavaScript基础语法
引入方式
第一种方式:内部脚本,将JS代码定义在HTML页面中。
- JavaScript代码必须位于<script></script>标签之间。
- 在HTML文档中,可以在任意地方,放置任意数量的<script>。
- 一般会把脚本置于<body>元素的底部,可改善显示速度。
例子:
1 | <script> |
第二种方式:外部脚本将, JS代码定义在外部 JS文件中,然后引入到 HTML页面中。
- 外部JS文件中,只包含JS代码,不包含<script>标签。
- 引入外部js的<script>标签,必须是双标签。
例子:
1 | <script src="js/demo.js"></script> |
- 注意:
- demo.js中只有js代码,没有
<script>标签。 <script>标签不能自闭合,假如只写一半会失效。
- demo.js中只有js代码,没有
书写语法
掌握了js的引入方式,那么接下来我们需要学习js的书写了,首先需要掌握的是js的书写语法,语法规则如下:
区分大小写:与 Java 一样,变量名、函数名以及其他一切东西都是区分大小写的
每行结尾的分号可有可无(建议写上)
大括号表示代码块
注释:
单行注释:// 注释内容
多行注释:/* 注释内容 */
| 输出语句 | 描述 |
|---|---|
| window.alert() | 在浏览器中弹出警告框,点确定后才能运行后面的js代码 |
| document.write() | 写入HTML,在浏览器中展示 |
| console.log() | 写入浏览器控制台,console是浏览器控制台对象 |
变量
js中主要通过如下3个关键字来声明变量:
| 关键字 | 解释 |
|---|---|
| var | 早期ECMAScript5中用于变量声明的关键字, 定义出来的变量属于全局变量 且可以重复声明 |
| let | ECMAScript6中新增的用于变量声明的关键字,只在代码块内生效,且不允许重复声明 |
| const | 声明常量的,常量一旦声明,不能修改,属于局部变量 |
注意:
JavaScript 是一门弱类型语言,变量可以存放不同类型的值 。
变量名规则和java一模一样:
- 组成字符可以是任何字母、数字、下划线(_)或美元符号($)
- 数字不能开头
- 建议使用驼峰命名
- 组成字符可以是任何字母、数字、下划线(_)或美元符号($)
1 | <script> |
数据类型和运算符
虽然js是弱数据类型的语言,但是js中也存在数据类型,js中的数据类型分为 :原始类型 和 引用类型,具体有如下类型
| 数据类型 | 描述 |
|---|---|
| number | 数字(整数、小数、NaN(Not a Number)) |
| string | 字符串,单双引皆可,和python完全一样 |
| boolean | 布尔。true,false |
| null | 对象为空 |
| undefined | 当声明的变量未初始化时,该变量的默认值是 undefined |
1 | //原始数据类型 |
js中的运算规则绝大多数和java中一样,具体运算符如下:
| 运算规则 | 运算符 |
|---|---|
| 算术运算符 | + , - , * , / , % , ++ , -- |
| 赋值运算符 | = , += , -= , *= , /= , %= |
| 比较运算符 | > , < , >= , <= , != , == , ===(全等运算符) 注意:== 会进行类型转换,=== 不会进行类型转换 |
| 逻辑运算符 | && , || , ! |
| 三元运算符 | 条件表达式 ? true_value: false_value |
1 | var age = 20; |
类型转换:
可以通过parseInt()函数来进行将其他类型转换成数值类型。(直接转化为字面意)
1 | // 类型转换 - 其他类型转为数字 |
0、null、undefined、"" 全部会被理解为false,除此之外全部理解成true。
1 | if(0) //false |
函数
大致有两种定义方法:
方法一
1 | function 函数名(参数1,参数2..){ |
注意:
形式参数不需要声明类型,并且JavaScript中不管什么类型都是let或者var去声明,加上也没有意义。
返回值也不需要声明类型,直接return即可
示例:
1 | function add(a, b){ |
方法二
1 | var functionName = function (参数1,参数2..){ |
示例:
1 | var add = function(a,b){ |
4.JavaScript对象
基本对象
Array
Array对象时用来定义数组的。常用语法格式有如下2种:
方式1:
1 | var 变量名 = new Array(元素列表); |
例如:
1 | var arr = new Array(1,2,3,4); //1,2,3,4 是存储在数组中的数据(元素) |
方式2:
1 | var 变量名 = [ 元素列表 ]; |
例如:
1 | var arr = [1,2,3,4]; //1,2,3,4 是存储在数组中的数据(元素) |
和java中一样,需要通过索引来获取数组中的值。
1 | arr[索引] = 值; |
注意:
- JavaScript中数组相当于java中的集合,数组的长度是可以变化的。而且JavaScript是弱数据类型的语言,所以数组中可以存储任意数据类型的值。
1 | var arr = [1,2,3,4]; |
属性和方法
| 属性 | 描述 |
|---|---|
| length | 设置或返回数组中元素的数量。 |
| 方法方法 | 描述 |
|---|---|
| forEach() | 遍历数组中的每个有值得元素,并调用一次传入的函数 |
| push() | 将新元素添加到数组的末尾,并返回新的长度 |
| splice() | 从数组中删除元素 |
forEach()函数
这个方法的参数,需要传递一个函数,而且这个函数接受一个参数,就是遍历时数组的值。
1
2
3
4//e是形参,接受的是数组遍历时的值
arr.forEach(function(e){
console.log(e);
})在ES6中,引入箭头函数的写法,语法类似java中lambda表达式
1
2
3arr.forEach((e) => {
console.log(e);
})push()函数
用于向数组的末尾添加元素的,其中函数的参数就是需要添加的元素。
1
2
3//向数组的末尾添加3个元素
arr.push(7,8,9);
console.log(arr);splice()函数
用来删除数组中的元素,函数中填入2个参数。
参数1:表示从哪个索引位置删除
参数2:表示删除元素的个数
1
2
3//从索引2的位置开始删,删除2个元素
arr.splice(2,2);
console.log(arr);
String
语法格式
String对象的创建方式有2种:
方式1:
1 | var 变量名 = new String("…") ; |
例如:
1 | var str = new String("Hello String"); |
方式2:
1 | var 变量名 = "…" ; |
例如:
1 | var str = 'Hello String'; |
属性和方法
| 属性 | 描述 |
|---|---|
| length | 字符串的长度。 |
| 方法 | 描述 |
|---|---|
| charAt() | 返回在指定位置的字符。 |
| indexOf() | 检索字符串。 |
| trim() | 去除字符串两边的空格 |
| substring() | 提取字符串中两个指定的索引号之间的字符。 |
charAt()函数:
用于返回在指定索引位置的字符,函数的参数就是索引。
1
console.log(str.charAt(4)); //o
indexOf()函数
用于检索指定内容在字符串中的索引位置的,返回值是索引,参数是指定的内容。
1
console.log(str.indexOf("lo")); //3
trim()函数
用于去除字符串两边的空格的。
1
2var s = str.trim();
console.log(s.length);substring()函数
用于截取字符串的,函数有2个参数,左闭右开。
1
console.log(s.substring(0,5)); //"Hello"
自定义对象
在 JavaScript 中自定义对象特别简单,其语法格式如下:
1 | var 对象名 = { |
我们可以通过如下语法调用属性:
1 | 对象名.属性名 |
通过如下语法调用函数:
1 | 对象名.函数名() |
示例:
1 | //自定义对象 |
json对象
JSON对象:JavaScript Object Notation,JavaScript对象标记法。是通过JavaScript标记法书写的文本。其格式如下:
1 | { |
其中,key必须使用引号并且是双引号标记,value可以是任意数据类型。
用处:
前后端交互时,我们需要传输数据,但是java中的对象我们该怎么去描述呢?
我们可以使用如图所示的xml格式,可以清晰的描述java中需要传递给前端的java对象。
1 | <user> |
但是xml格式存在如下问题:
- 标签需要编写双份,占用带宽,浪费资源
- 解析繁琐
所以我们可以使用json来替代,直接传输{"name":"Tom", "age":18, "addr":["北京","上海","西安"]}
输入如下代码:
1 | var jsonstr = '{"name":"Tom", "age":18, "addr":["北京","上海","西安"]}'; |
因为上述是一个json字符串,不是json对象,我们需要借助如下函数来进行json字符串和json对象的转换。
1 | var obj = JSON.parse(jsonstr); |
我们也可以通过如下函数将json对象再次转换成json字符串。添加如下代码:
1 | alert(JSON.stringify(obj)); //{"name":"Tom", "age":18, "addr":["北京","上海","西安"]} |
BOM对象
BOM的全称是Browser Object Model,翻译过来是浏览器对象模型。也就是JavaScript将浏览器的各个组成部分封装成了对象。
我们要操作浏览器的部分功能,可以通过操作BOM对象的相关属性或者函数来完成。
例如:我们想要将浏览器的地址改为http://www.baidu.com,我们就可以通过BOM中提供的location对象的href属性来完成,代码如下:location.href='http://www.baidu.com'
BOM中提供了如下5个对象:
| 对象名称 | 描述 |
|---|---|
| Window | 浏览器窗口对象 |
| Navigator | 浏览器对象 |
| Screen | 屏幕对象 |
| History | 历史记录对象 |
| Location | 地址栏对象 |
Window对象
window对象指的是浏览器窗口对象,是JavaScript的全部对象,所以对于window对象,我们可以直接使用,并且对于window对象的方法和属性,我们可以省略window.
例如:我们之前学习的alert()函数其实是属于window对象的,其完整的代码如下:
1 | window.alert('hello'); |
因为可以省略window. 所以可以简写成
1 | alert('hello') |
所以对于window对象的属性和方法,我们都是采用简写的方式。
window对象提供了获取其他BOM对象的属性:
| 属性 | 描述 |
|---|---|
| history | 用于获取history对象 |
| location | 用于获取location对象 |
| Navigator | 用于获取Navigator对象 |
| Screen | 用于获取Screen对象 |
也就是说我们要使用location对象,只需要通过代码window.location或者简写location即可使用
window也提供了一些常用的函数
| 函数 | 描述 |
|---|---|
| alert() | 显示带有一段消息和一个确认按钮的警告框。 |
| comfirm() | 显示带有一段消息以及确认按钮和取消按钮的对话框。 |
| setInterval() | 按照指定的周期(以毫秒计)来调用函数或计算表达式。 |
| setTimeout() | 在指定的毫秒数后调用函数或计算表达式。 |
confirm()函数:弹出确认框,并且提供用户2个按钮,分别是确认和取消。
这个函数有一个返回值,当用户点击确认时,返回true,点击取消时,返回false。我们根据返回值来决定是否执行后续操作。修改代码如下:再次运行,可以查看返回值true或者false
1
2var flag = confirm("您确认删除该记录吗?");
alert(flag);setInterval(fn,毫秒值):定时器,用于周期性的执行某个功能,并且是循环执行。该函数需要传递2个参数:
fn:函数,需要周期性执行的功能代码
毫秒值:间隔时间
1
2
3
4
5var i = 0;
setInterval(function(){
i++;
console.log("定时器执行了"+i+"次");
},2000);setTimeout(fn,毫秒值) :定时器,只会在一段时间后执行一次功能。参数和上述setInterval一致
1
2
3setTimeout(function(){
alert("JS");
},3000);浏览器打开,3s后弹框,关闭弹框,发现再也不会弹框了。
Location对象
location是指代浏览器的地址栏对象,对于这个对象,我们常用的是href属性,用于获取或者设置浏览器的地址信息,添加如下代码:
1 | //获取浏览器地址栏信息 |
DOM对象
Document Object Model 文档对象模型。也就是 JavaScript 将 HTML 文档的各个组成部分封装为对象。
封装的对象分为
- Document:整个文档对象
- Element:元素对象
- Attribute:属性对象
- Text:文本对象
- Comment:注释对象
JavaScript会将html文档转换为DOM树
1 | <html lang="en"> |
1 | graph TB |
主要作用如下:
- 改变 HTML 元素的内容
- 改变 HTML 元素的样式(CSS)
- 对 HTML DOM 事件作出反应
- 添加和删除 HTML 元素
总而达到动态改变页面效果目的
获取DOM对象
HTML中的Element对象可以通过Document对象获取,而Document对象是通过window对象获取的。
document对象提供的用于获取Element元素对象的api如下表所示:
| 函数 | 描述 |
|---|---|
| document.getElementById() | 根据id属性值获取,返回单个Element对象 |
| document.getElementsByTagName() | 根据标签名称获取,返回Element对象数组 |
| document.getElementsByName() | 根据name属性值获取,返回Element对象数组 |
| document.getElementsByClassName() | 根据class属性值获取,返回Element对象数组 |
首先在准备如下页面代码:
1 |
|
document.getElementById(): 根据标签的id属性获取标签对象,id是唯一的,所以获取到是单个标签对象。
1
2
3
4<script>
var img = document.getElementById('h1');
alert(img); //[object HTMLlmageElement]
</script>document.getElementsByTagName() : 根据标签的名字获取标签对象,同名的标签有很多,所以返回值是数组。
1
2
3
4var divs = document.getElementsByTagName('div');
for (let i = 0; i < divs.length; i++) {
alert(divs[i]); //浏览器输出2次:[object HTMLDivElement]
}document.getElementsByName() :根据标签的name的属性值获取标签对象,name属性值可以重复,所以返回值是一个数组。
1
2
3
4var ins = document.getElementsByName('hobby');
for (let i = 0; i < ins.length; i++) {
alert(ins[i]); //浏览器输出3次:[object HTMLInputElement]
}document.getElementsByClassName() : 根据标签的class属性值获取标签对象,class属性值也可以重复,返回值是数组。
1
2
3
4var divs = document.getElementsByClassName('cls');
for (let i = 0; i < divs.length; i++) {
alert(divs[i]); //浏览器输出2次:[object HTMLDivElement]
}
操作属性
那么获取到标签了,我们通过查询文档资料JavaScript 和 HTML DOM 参考手册 (w3school.com.cn),得到需要操作的属性
例如:
1 | //1. 点亮灯泡 : src 属性值 |
5.JavaScript事件
事件绑定
JavaScript对于事件的绑定提供了2种方式:
方式1:通过html标签中的事件属性进行绑定
例如一个按钮,我们对于按钮可以绑定单机事件,可以借助标签的onclick属性,属性值指向一个函数。
1
<input type="button" id="btn1" value="事件绑定1" onclick="on()">
很明显没有on函数,所以我们需要创建该函数,代码如下:
1
2
3
4
5<script>
function on(){
alert("按钮1被点击了...");
}
</script>点击按钮时弹出弹窗:按钮1被点击了...
方式2:通过DOM中Element元素的事件属性进行绑定
依据我们学习过得DOM的知识点,我们知道html中的标签被加载成element对象,所以我们也可以通过element对象的属性来操作标签的属性。
此时我们再次添加一个按钮,代码如下:
1
<input type="button" id="btn2" value="事件绑定2">
我们可以先通过id属性获取按钮对象,然后操作对象的onclick属性来绑定事件,代码如下:
1
2
3document.getElementById('btn2').onclick = function(){
alert("按钮2被点击了...");
}浏览器刷新页面,点击第二个按钮弹出弹窗:按钮2被点击了...
需要注意的是:事件绑定的函数,只有在事件被触发时,函数才会被调用。
常见事件
上面案例中使用到了 onclick
事件属性,那都有哪些事件属性供我们使用呢?下面就给大家列举一些比较常用的事件属性
| 事件属性名 | 说明 |
|---|---|
| onclick | 鼠标单击事件 |
| onblur | 元素失去焦点 |
| onfocus | 元素获得焦点 |
| onload | 某个页面或图像被完成加载 |
| onsubmit | 当表单提交时触发该事件 |
| onmouseover | 鼠标被移到某元素之上 |
| onmouseout | 鼠标从某元素移开 |
onload
1
<body onload="load()">
1
2
3
4//onload : 页面/元素加载完成后触发
function load(){
console.log("页面加载完成...")
}页面加载完后控制台显示
onclick
1
<input id="b1" type="button" value="单击事件" onclick="fn1()">
1
2
3
4//onclick: 鼠标点击事件
function fn1(){
console.log("我被点击了...");
}onblur、onfocus
1
<input type="text" name="username" onblur="bfn()" onfocus="ffn()" onkeydown="kfn()">
1
2
3
4
5
6
7
8
9//onfocus: 元素获得焦点
function ffn(){
console.log("获得焦点...");
}
//onkeydown: 某个键盘的键被按下
function kfn(){
console.log("键盘被按下了...");
}当鼠标点击这个框或者使用TAB按键进入时触发onfocus
onkeydown
1
<input type="text" name="username" onblur="bfn()" onfocus="ffn()" onkeydown="kfn()">
1
2
3
4//onkeydown: 某个键盘的键被按下
function kfn(){
console.log("键盘被按下了...");
}onmouseover、onmouseout
1
<table width="800px" border="1" cellspacing="0" align="center" onmouseover="over()" onmouseout="out()">
1
2
3
4
5
6
7
8//onmouseover: 鼠标移动到元素之上
function over(){
console.log("鼠标移入了...")
}
//onmouseout: 鼠标移出某元素
function out(){
console.log("鼠标移出了...")
}onsubmit
1
<form action="" style="text-align: center;" onsubmit="subfn()">
1
2
3
4//onsubmit: 提交表单事件
function subfn(){
alert("表单被提交了...");
}
6.VUE
引入Vue
第一步:在html文件同级创建js目录,将vue.js文件拷贝到js目录
第二步:然后在<head>编写<script>标签来引入vue.js文件,代码如下:
1 | <script src="js/vue.js"></script> |
第三步:在js代码区域定义vue对象,代码如下:
1 | <script> |
在创建vue对象时,有几个常用的属性:
- el: 用来指定哪儿些标签受 Vue 管理。 该属性取值
#app中的app需要是受管理的标签的id属性值 - data: 用来定义数据模型
- methods: 用来定义函数。这个我们在后面就会用到
第四步:在html区域编写视图,其中{{}}是插值表达式,用来将vue对象中定义的model展示到页面上的
1 | <body> |
浏览器中打开发现只要修改input中的内容,旁边显示的文字也会跟着改变。
这是因为发生了双向数据绑定(Vue的特点)
Vue指令
HTML 标签上带有 v- 前缀的特殊属性,都是vue指令。
在vue中,通过大量的指令来实现数据绑定到视图的,所以接下来我们需要学习vue的常用指令,如下表所示:
| 指令 | 作用 |
|---|---|
| v-bind | 为HTML标签绑定属性值,如设置 href , css样式等 |
| v-model | 在表单元素上创建双向数据绑定 |
| v-on | 为HTML标签绑定事件 |
| v-if | 条件性的渲染某元素,判定为true时渲染,否则不渲染 |
| v-else | 同上 |
| v-else-if | 同上 |
| v-show | 根据条件展示某元素,区别在于切换的是display属性的值 |
| v-for | 列表渲染,遍历容器的元素或者对象的属性 |
v-bind和v-model
先定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
url: "https://www.baidu.com"
}
})v-bind: 为HTML标签绑定属性值,如设置 href , css样式等。当vue对象中的数据模型发生变化时,标签的属性值会随之发生变化
示例:
给<a>标签的href属性赋值,并且值应该来自于vue对象的数据模型中的url变量。所以编写如下代码:
1
2
3
4
5<div id="app">
<a v-bind:href="url">链接1</a>
</div>在上述的代码中,v-bind指令是可以省略的,但是
:不能省略,所以超链接的代码也可以编写如下:1
<a :href="url">链接2</a>
v-model: 在表单元素上创建双向数据绑定。
什么是双向?
vue对象的data属性中的数据变化,视图展示会一起变化
视图数据发生变化,vue对象的data属性中的数据也会随着变化。
data属性中数据变化,我们知道可以通过赋值来改变,但是视图数据为什么会发生变化呢?只有表单项标签!所以双向绑定一定是使用在表单项标签上的。编写如下代码:
1
<input type="text" v-model="url">
打开浏览器后,发现我们只是改变了表单数据,之前超链接的绑定的数据值也发生了变化。
这是因为我们双向绑定,在视图发生变化时,同时vue的data中的数据模型也会随着变化。
v-on
v-on: 用来给html标签绑定事件的。需要注意的是如下2点:
v-on语法给标签的事件绑定的函数,必须是vue对象种声明的函数
v-on语法绑定事件时,事件名相比较js中的事件名,没有on
例如:在js中,事件绑定demo函数
1
<input onclick="demo()">
vue中,事件绑定demo函数
1
<input v-on:click="demo()">
在vue对象的methods属性中定义事件绑定时需要的handle()函数:
1 | <script> |
然后我们给第一个按钮,通过v-on指令绑定单击事件:
1 | <input type="button" value="点我一下" v-on:click="handle()"> |
同样,v-on也存在简写方式,即v-on: 可以替换成@:
1 | <input type="button" value="点我一下" @click="handle()"> |
同理:@blur,@focus 等
v-if和v-show
| 指令 | 描述 |
|---|---|
| v-if、if-else、else | 条件性的渲染某元素,判定为true时渲染,否则不渲染 |
| v-show | 根据条件展示某元素,区别在于切换的是display属性的值 |
需求是当我们改变年龄时,需要动态判断年龄的值,呈现对应的年龄的文字描述。
年轻人,我们需要使用条件判断age<=35,中年人我们需要使用条件判断age>35 && age<60,其他情况是老年人。
通过v-if指令编写如下代码:
1 | <body> |
打开浏览器后,通过改变输入框中的数字,后面就会显示判定结果。
v-show和v-if的作用效果是一样的,只是原理不一样:
1 | 年龄<input type="text" v-model="age">经判定,为: |
在浏览器中查看,发现:
v-if指令,不满足条件的标签代码直接没了,而v-show指令中,不满足条件的代码依然存在,只是添加了css样式来控制标签不去显示。
1 | <body> |
v-for
v-for: 从名字我们就能看出,这个指令是用来遍历的。其语法格式如下:
1 | <标签 v-for="变量名 in 集合模型数据"> |
需要循环那个标签,v-for 指令就写在那个标签上。
有时我们遍历时需要使用索引(索引变量是从0开始),那么v-for指令遍历的语法格式如下:
1 | <标签 v-for="(变量名,索引变量) in 集合模型数据"> |
接下来,我们再VS Code中创建名为16. Vue-指令-v-for.html的文件编写代码演示,提前准备如下代码:
1 | <body> |
浏览器打开,呈现如下效果:
北京
上海
西安
成都
深圳
1 : 北京
2 : 上海
3 : 西安
4 : 成都
5 : 深圳
生命周期
vue的生命周期:指的是vue对象从创建到销毁的过程。vue的生命周期包含8个阶段:每触发一个生命周期事件,会自动执行一个生命周期方法,这些生命周期方法也被称为钩子方法。其完整的生命周期如下图所示:
| 状态 | 阶段周期 |
|---|---|
| beforeCreate | 创建前 |
| created | 创建后 |
| beforeMount | 挂载前 |
| mounted | 挂载完成 |
| beforeUpdate | 更新前 |
| updated | 更新后 |
| beforeDestroy | 销毁前 |
| destroyed | 销毁后 |
下图是 Vue 官网提供的从创建 Vue 到效果 Vue 对象的整个过程及各个阶段对应的钩子函数:

其中我们需要重点关注的是mounted,其他的我们了解即可。
mounted:挂载完成,Vue初始化成功,HTML页面渲染成功。我们一般用于页面初始化自动的ajax(一种异步交互技术)请求后台数据
编写mounted声明周期的钩子函数,与methods同级,代码如下:
1 | <script> |
浏览器打开,运行结果如下:我们发现,自动打印了这句话,因为页面加载完成,vue对象创建并且完成了挂载,此时自动触发mounted所绑定的钩子函数,然后自动执行,弹框。(一般会在这个时候发送异步请求到服务端请求数据)
7.Ajax
Ajax:Asynchronous JavaScript And XML,异步的JavaScript和XML。其作用有如下2点:
- 与服务器进行数据交换:通过Ajax可以给服务器发送请求,并获取服务器响应的数据。
- 异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术,如:搜索联想、用户名是否可用的校验等等。
Ajax作用
我们详细的解释一下Ajax技术的2个作用
与服务器进行数据交互
前端可以通过Ajax技术,向后台服务器发起请求,后台服务器接受到前端的请求,从数据库中获取前端需要的资源,然后响应给前端。
前端再通过vue技术,可以将数据展示到页面上,这样用户就能看到完整的页面了。
异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术。
当我们再百度搜索java时,下面的联想数据是通过Ajax请求从后台服务器得到的,在整个过程中,我们的Ajax请求不会导致整个百度页面的重新加载,并且只针对搜索栏这局部模块的数据进行了数据的更新,不会对整个页面的其他地方进行数据的更新,这样就大大提升了页面的加载速度,用户体验高。
异步非阻塞式web开发:
异步非阻塞式Web开发是一种网络应用程序的编程模型,它允许在等待某些任务完成时,继续执行其他任务。
异步非阻塞式Web开发中,一个任务在开始执行后,如果需要等待一个操作完成(例如:读写文件、网络通信等),程序会继续执行其他任务,而不需要等待这个操作完成。当这个操作完成后,程序会通知相关的任务,然后任务再继续执行后续的操作。
原生Ajax
1、准备服务器端数据地址
http://yapi.smart-xwork.cn/mock/169327/emp/list(返回的是JSON格式内容)
2、创建XMLHttpRequest 对象:用于和服务器交换数据,也是原生Ajax请求的核心对象,提供了各种方法。
3、向服务器发送请求,调用对象的open()方法设置请求的参数信息,例如请求地址,请求方式。然后调用send()方法向服务器发送请求。
4、我们通过绑定事件的方式,来获取服务器响应的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>原生Ajax</title>
</head>
<body>
<input type="button" value="获取数据" onclick="getData()">
<div id="div1"></div>
</body>
<script>
function getData(){
//1. 创建XMLHttpRequest
var xmlHttpRequest = new XMLHttpRequest();
//2. 发送异步请求
xmlHttpRequest.open('GET','http://yapi.smart-xwork.cn/mock/169327/emp/list');
xmlHttpRequest.send();//发送请求
//3. 获取服务响应数据
xmlHttpRequest.onreadystatechange = function(){
//此处判断 4 表示浏览器已经完全接受到Ajax请求得到的响应, 200表示这是一个正确的Http请求,没有错误
if(xmlHttpRequest.readyState == 4 && xmlHttpRequest.status == 200){
document.getElementById('div1').innerHTML = xmlHttpRequest.responseText;
}
}
}
</script>
</html>
Axios
上述原生的Ajax请求的代码编写起来还是比较繁琐的,所以通常使用更加简单的发送Ajax请求的技术Axios 。Axios是对原生的AJAX进行封装,简化书写。
基本使用
Axios的使用比较简单,主要分为2步:
引入Axios文件
1
<script src="js/axios-0.18.0.js"></script>
使用Axios发送请求,并获取响应结果,官方提供的api很多,此处给出2种,如下
发送 get 请求
1
2
3
4
5
6axios({
method:"get",
url:"http://localhost:8080/ajax-demo1/aJAXDemo1?username=zhangsan"
}).then(function (resp){
alert(resp.data);
})或者可以这么写
1
2
3
4
5
6axios({
method:"get",
url:"http://localhost:8080/ajax-demo1/aJAXDemo1?username=zhangsan"
}).then(result => {
console.log(result.data);
})发送 post 请求
1
2
3
4
5
6
7axios({
method:"post",
url:"http://localhost:8080/ajax-demo1/aJAXDemo1",
data:"username=zhangsan"
}).then(function (resp){
alert(resp.data);
});
axios()是用来发送异步请求的,小括号中使用 js的JSON对象传递请求相关的参数:
- method属性:用来设置请求方式的。取值为 get 或者 post。
- url属性:用来书写请求的资源路径。如果是 get 请求,需要将请求参数拼接到路径的后面,格式为: url?参数名=参数值&参数名2=参数值2。
- data属性:作为请求体被发送的数据。也就是说如果是 post 请求的话,数据需要作为 data 属性的值。
then() 需要传递一个匿名函数。我们将 then()中传递的匿名函数称为 回调函数,意思是该匿名函数在发送请求时不会被调用,而是在成功响应后调用的函数。而该回调函数中的 resp 参数是对响应的数据进行封装的对象,通过 resp.data 可以获取到响应的数据。
在
axios的上下文中,.then(result => { ... })中的result对象通常包含以下属性:data: 实际的响应数据,我们需要的JSON内容就在其中。status: HTTP 状态码。statusText: HTTP 状态文本。headers: 响应头信息。config: 请求的配置对象。
请求方法的别名
Axios还针对不同的请求,提供了别名方式的api,具体如下(方括号中是可选参数):
| 方法 | 描述 |
|---|---|
axios.get(url [, config]) |
发送get请求 |
axios.delete(url [, config]) |
发送delete请求 |
axios.post(url [, data[, config]]) |
发送post请求 |
axios.put(url [, data[, config]]) |
发送put请求 |
我们目前只关注get和post请求,所以在上述的入门案例中,我们可以将get请求代码改写成如下:
1 | axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { |
post请求改写成如下:
1 | axios.post("http://yapi.smart-xwork.cn/mock/169327/emp/deleteById","id=1").then(result => { |
数据动态加载
使用Vue中的钩子 函数mounted (),可以自动加载并将json赋值
其中请求服务端返回的数据位JSON格式,其中的data提供了一个数组,是我们需要的
1 | <body> |
8.前端工程化
略
后端深邃难觅迹
Maven
Maven是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。
它基于项目对象模型(Project Object Model , 简称: POM)的概念,通过一小段描述信息来管理项目的构建、报告和文档。
官网:https://maven.apache.org/
Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性组织。
开源项目:https://www.apache.org/index.html#projects-list
Maven的作用
- 依赖管理
- 统一项目结构
- 项目构建
依赖管理:
方便快捷的管理项目依赖的资源(jar包,平时使用需要手动下载并导入),避免版本冲突问题
当使用maven进行项目依赖(jar包)管理,则很方便的可以解决这个问题。 我们只需要在maven项目的pom.xml文件中,添加一段配置即可实现。
统一项目结构 :
- 提供标准、统一的项目结构
在项目开发中,当你使用不同的开发工具 (如:Eclipse、Idea),创建项目工程时,目录结构是不同的
若我们创建的是一个maven工程,是可以帮我们自动生成统一、标准的项目目录结构:

目录说明:
- src/main/java: java源代码目录
- src/main/resources: 配置文件信息
- src/test/java: 测试代码
- src/test/resources: 测试配置文件信息
项目构建 :
- maven提供了标准的、跨平台(Linux、Windows、MacOS) 的自动化项目构建方式
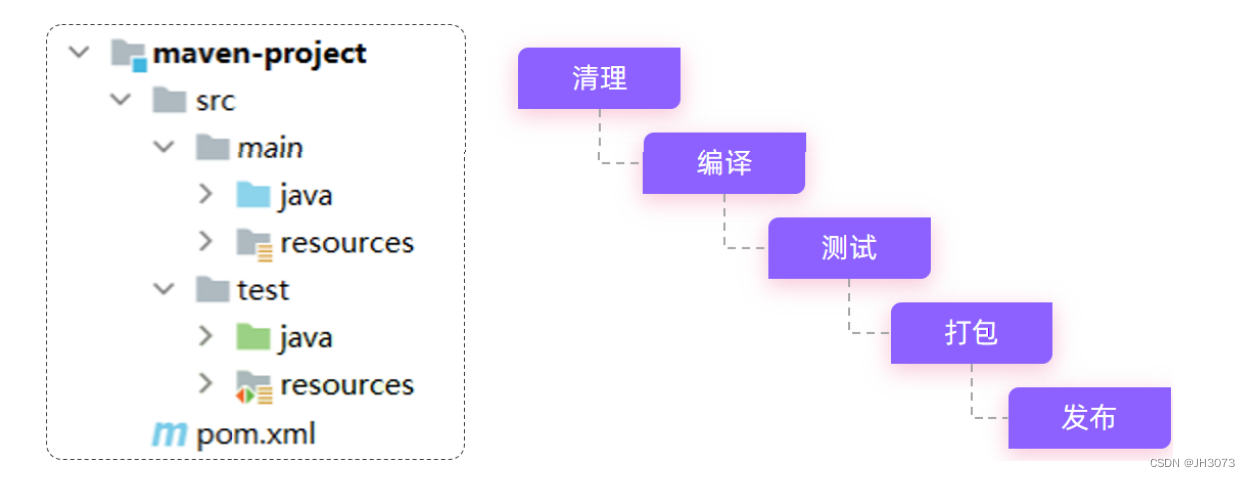
如上图所示我们开发了一套系统,代码需要进行编译、测试、打包、发布,这些操作如果需要反复进行就显得特别麻烦,而Maven提供了一套简单的命令来完成项目构建。
Maven模型
- 项目对象模型 (Project Object Model)
- 依赖管理模型(Dependency)
- 构建生命周期/阶段(Build lifecycle & phases)
1). 构建生命周期/阶段(Build lifecycle & phases)
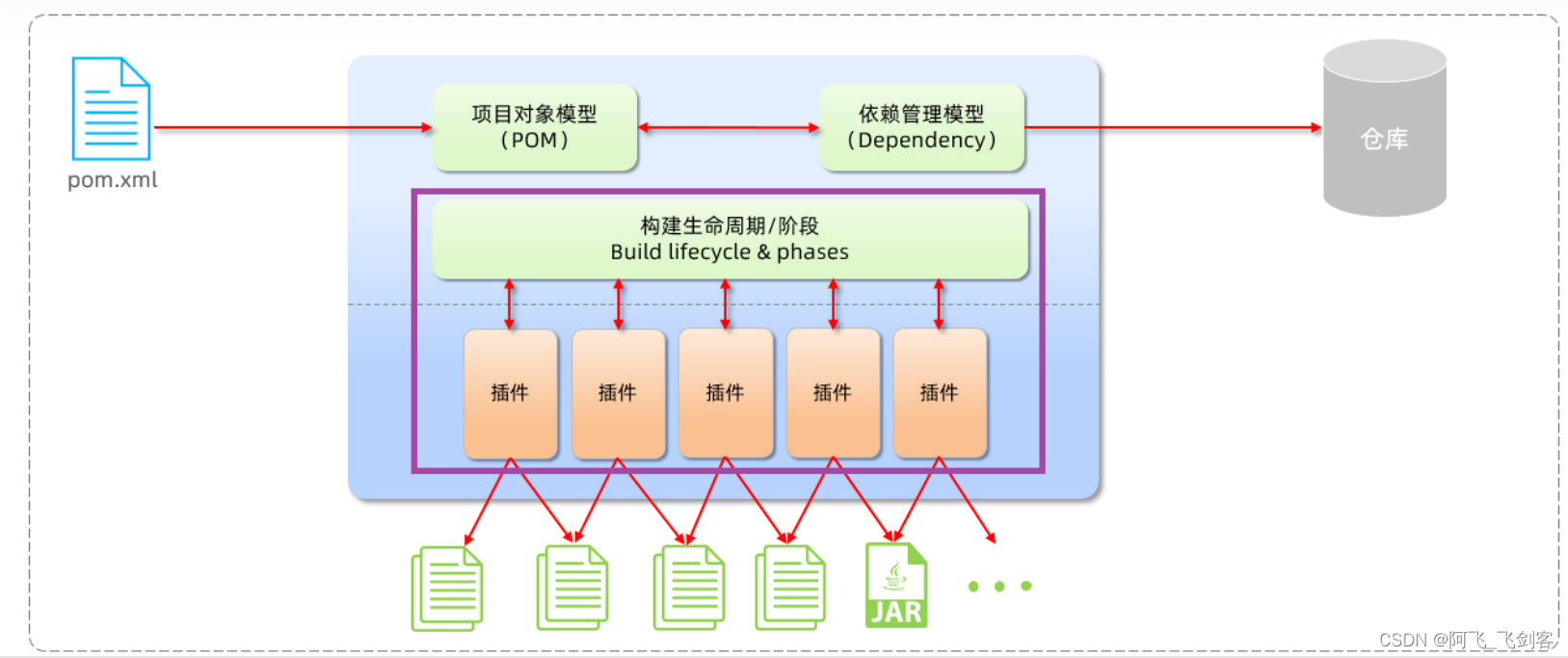
以上图中紫色框起来的部分,就是用来完成标准化构建流程 。当我们需要编译,Maven提供了一个编译插件供我们使用;当我们需要打包,Maven就提供了一个打包插件供我们使用等。
2). 项目对象模型 (Project Object Model)
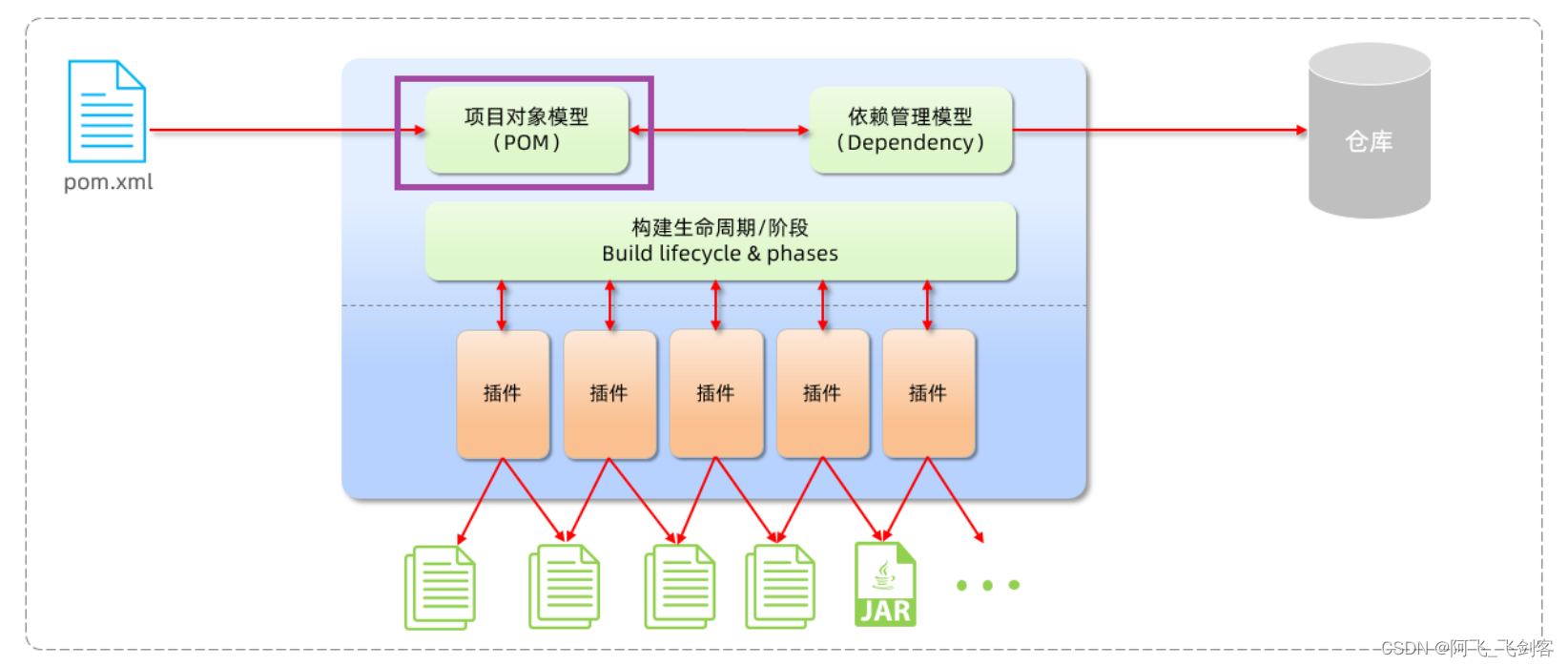
上图中紫色框起来的部分属于项目对象模型,将我们自己的项目抽象成一个对象模型,有自己专属的坐标。 什么是对象模型 POM (Project Object Model) :指的是项目对象模型,用来描述当前的maven项目。它是通过pom.xml文件来实现的。
1 |
|
- Maven 坐标主要由以下元素组成:
- groupId(必须): 项目组 ID,定义当前 Maven 项目隶属的组织或公司,通常是唯一的。它的取值一般是项目所属公司或组织的网址或 URL 的反写,例如 com.baidu.www。
- artifactId(必须): 项目 ID,通常是项目的名称。
- version(必须):版本。
- packaging(可选):项目的打包方式,默认值为 jar。
我们可以使用坐标来为自己的项目导入资源,同样,其他人也可以通过我们的项目坐标导入我们的资源。
3). 依赖管理模型(Dependency)
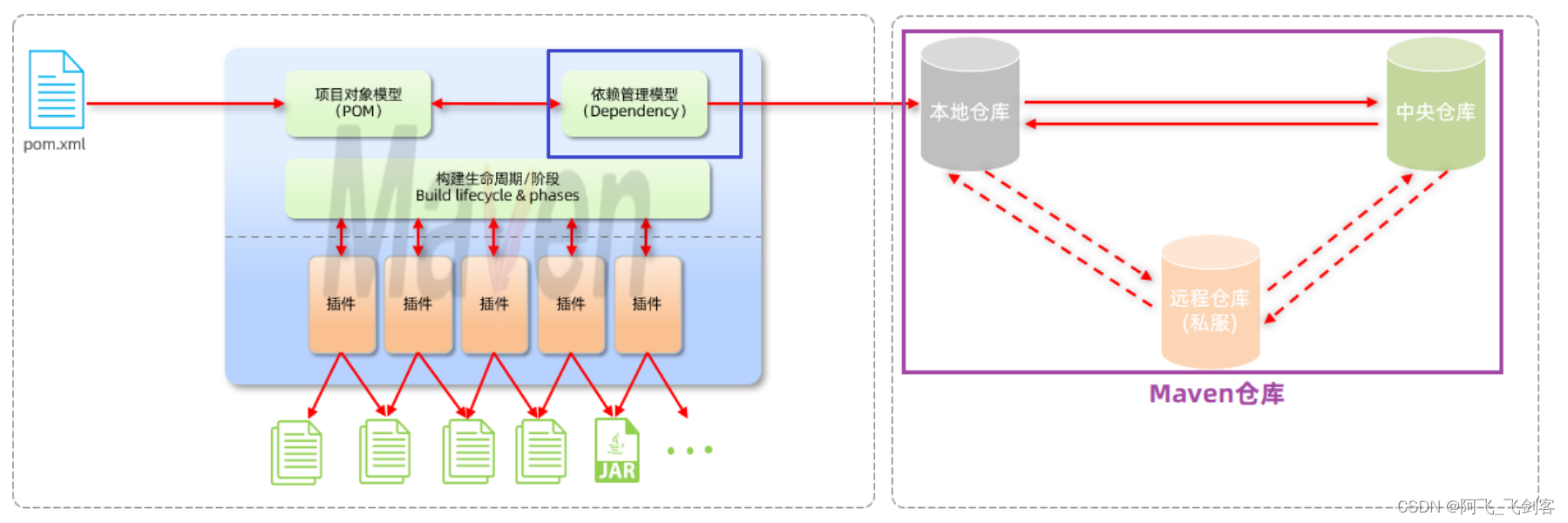
以上图中紫色框起来的部分属于依赖管理模型,是使用坐标来描述当前项目依赖哪些第三方jar包。当前项目所依赖的jar包需要从仓库中进行获取。 仓库:用于存储资源,管理各种jar包。
仓库的本质就是一个目录(文件夹),这个目录被用来存储开发中所有依赖(就是jar包)和插件。
Maven仓库分为: (1)本地仓库:自己计算机上的一个目录(用来存储jar包) (2)中央仓库:由Maven团队维护的全球唯一的。仓库地址:maven_repo (3)远程仓库(私服):一般由公司团队搭建的私有仓库
jar包的查找顺序为: 本地仓库 --> 远程仓库 --> 中央仓库
依赖管理
依赖配置
依赖:指当前项目运行所需要的jar包。一个项目中可以引入多个依赖:
例如:在当前工程中,我们需要用到logback来记录日志,此时就可以在maven工程的pom.xml文件中,引入logback的依赖。具体步骤如下:
在pom.xml中编写
<dependencies>标签在
<dependencies>标签中使用<dependency>引入坐标定义坐标的
groupId、artifactId、version
1 | <dependencies> |
- 点击刷新按钮,引入最新加入的坐标
- 刷新依赖:保证每一次引入新的依赖,或者修改现有的依赖配置,都可以加入最新的坐标
注意事项:
- 如果引入的依赖,在本地仓库中不存在,将会连接远程仓库 / 中央仓库,然后下载依赖(这个过程会比较耗时,耐心等待)
- 如果不知道依赖的坐标信息,可以到mvn的中央仓库(https://mvnrepository.com/)中搜索
依赖传递
传递性
早期我们没有使用maven时,向项目中添加依赖的jar包,需要把所有的jar包都复制到项目工程下。如下图所示,需要logback-classic时,由于logback-classic又依赖了logback-core和slf4j,所以必须把这3个jar包全部复制到项目工程下。
在maven中,当项目中需要使用logback-classic时,只需要在pom.xml配置文件中,添加logback-classic的依赖坐标即可。
在pom.xml文件中只添加了logback-classic依赖,但由于maven的依赖具有传递性,所以会自动把所依赖的其他jar包也一起导入。
排除依赖
假设A依赖B,B依赖C,如果A不想将C依赖进来,可以通过排除依赖来实现。
- 排除依赖:指主动断开依赖的资源。(被排除的资源无需指定版本)
1 | <dependency> |
依赖范围
在项目中导入依赖的jar包后,默认情况下,可以在任何地方使用。
如果希望限制依赖的使用范围,可以通过
作用范围:
- 主程序范围有效(main文件夹范围内)
- 测试程序范围有效(test文件夹范围内)
- 是否参与打包运行(package指令范围内)
1 | <!-- junit --> |
给junit依赖通过scope标签指定依赖的作用范围。 那么这个依赖就只能作用在测试环境,其他环境下不能使用。
scope标签的取值范围:
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
生命周期
Maven的生命周期就是为了对所有的构建过程进行抽象和统一。 描述了一次项目构建,经历哪些阶段。
在Maven出现之前,项目构建的生命周期就已经存在,软件开发人员每天都在对项目进行清理,编译,测试及部署。虽然大家都在不停地做构建工作,但公司和公司间、项目和项目间,往往使用不同的方式做类似的工作。
Maven从大量项目和构建工具中学习和反思,然后总结了一套高度完美的,易扩展的项目构建生命周期。这个生命周期包含了项目的清理,初始化,编译,测试,打包,集成测试,验证,部署和站点生成等几乎所有构建步骤。
Maven对项目构建的生命周期划分为3套(相互独立):

clean:清理工作。
default:核心工作。如:编译、测试、打包、安装、部署等。
site:生成报告、发布站点等。
三套生命周期又包含哪些具体的阶段呢, 我们来看下面这幅图:
我们看到这三套生命周期,里面有很多很多的阶段,这么多生命周期阶段,其实我们常用的并不多,主要关注以下几个:
• clean:移除上一次构建生成的文件
• compile:编译项目源代码
• test:使用合适的单元测试框架运行测试(junit)
• package:将编译后的文件打包,如:jar、war等
• install:安装项目到本地仓库
Maven的生命周期是抽象的,这意味着生命周期本身不做任何实际工作。在Maven的设计中,实际任务(如源代码编译)都交由插件来完成。
生命周期的顺序是:clean --> validate --> compile --> test --> package --> verify --> install --> site --> deploy
我们需要关注的就是:clean --> compile --> test --> package --> install
说明:在同一套生命周期中,我们在执行后面的生命周期时,前面的生命周期都会执行。
思考:当运行package生命周期时,clean、compile生命周期会不会运行?
clean不会运行,compile会运行。 因为compile与package属于同一套生命周期,而clean与package不属于同一套生命周期。
SpringBoot
1. HTTP协议
浏览器和服务器是按照HTTP协议进行数据通信的。
HTTP协议又分为:请求协议和响应协议
- 请求协议:浏览器将数据以请求格式发送到服务器
- 包括:请求行、请求头 、请求体
- 响应协议:服务器将数据以响应格式返回给浏览器
- 包括:响应行 、响应头 、响应体
请求协议
在HTTP1.1版本中,浏览器访问服务器的几种方式:
| 请求方式 | 请求说明 |
|---|---|
| GET | 获取资源。 向特定的资源发出请求。例:http://www.baidu.com/s?wd=nicccce |
| POST | 传输实体主体。 向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方式。 因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法,例如:DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。 |
| HEAD | 获得报文首部。 HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。通常用于确认URI的有效性及资源更新时间等。 |
| PUT | 传输文件。 PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。 |
| DELETE | 删除文件。 请求服务器删除Request-URI所标识的资源 |
| TRACE | 追踪路径。 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | 要求用隧道协议连接代理。 HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
在我们实际应用中常用的也就是 :GET、POST
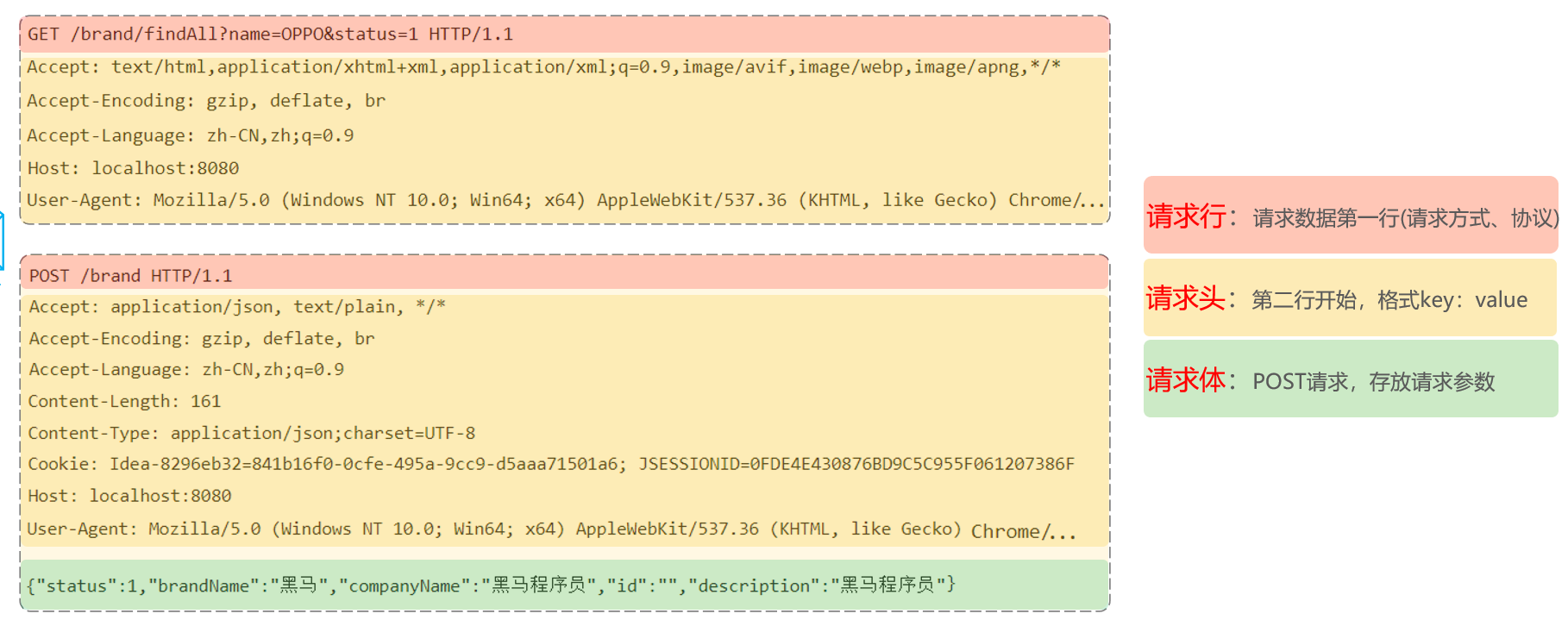
GET方式的请求协议:
请求行 :HTTP请求中的第一行数据。由:
请求方式、资源路径、协议/版本组成(之间使用空格分隔)- 请求方式:GET
- 资源路径:/brand/findAll?name=OPPO&status=1
- 请求路径:/brand/findAll
- 请求参数:name=OPPO&status=1
- 请求参数是以key=value形式出现
- 多个请求参数之间使用
&连接
- 请求路径和请求参数之间使用
?连接
- 协议/版本:HTTP/1.1
- 请求方式:GET
请求头 :第二行开始,上 图黄色部分内容就是请求头。格式为key: value形式
- http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
常见的HTTP请求头有:
1
2
3
4
5
6
7
8
9
10
11
12
13Host: 表示请求的主机名
User-Agent: 浏览器版本。 例如:Chrome浏览器的标识类似Mozilla/5.0 ...Chrome/79 ,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...)like Gecko
Accept:表示浏览器能接收的资源类型,如text/*,image/*或者*/*表示所有;
Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate等。
Content-Type:请求主体的数据类型
Content-Length:数据主体的大小(单位:字节)
举例说明:服务端可以根据请求头中的内容来获取客户端的相关信息,有了这些信息服务端就可以处理不同的业务需求。
比如:
- 不同浏览器解析HTML和CSS标签的结果会有不一致,所以就会导致相同的代码在不同的浏览器会出现不同的效果
- 服务端根据客户端请求头中的数据获取到客户端的浏览器类型,就可以根据不同的浏览器设置不同的代码来达到一致的效果(这就是我们常说的浏览器兼容问题)
- 请求体 :存储请求参数
- GET请求的请求参数在请求行中,故不需要设置请求体
POST方式的请求协议:
- 请求行(以上图中红色部分):包含请求方式、资源路径、协议/版本
- 请求方式:POST
- 资源路径:/brand
- 协议/版本:HTTP/1.1
- 请求头(以上图中黄色部分)
- 请求体(以上图中绿色部分) :存储请求参数
- 请求体和请求头之间是有一个空行隔开(作用:用于标记请求头结束)
GET请求和POST请求的区别:
| 区别方式 | GET请求 | POST请求 |
|---|---|---|
| 请求参数 | 请求参数在请求行中。 例:/brand/findAll?name=OPPO&status=1 |
请求参数在请求体中 |
| 请求参数长度 | 请求参数长度有限制(浏览器不同限制也不同) | 请求参数长度没有限制 |
| 安全性 | 安全性低。原因:请求参数暴露在浏览器地址栏中。 | 安全性相对高 |
响应协议
格式
与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体
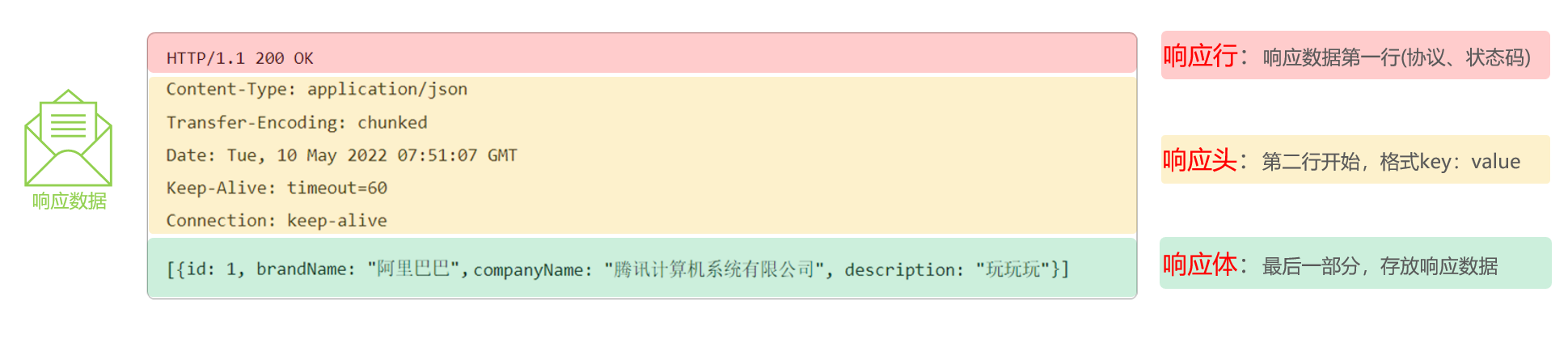
响应行(以上图中红色部分):响应数据的第一行。响应行由
协议及版本、响应状态码、状态码描述组成- 协议/版本:HTTP/1.1
- 响应状态码:200
- 状态码描述:OK
响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式
- http是个无状态的协议,所以可以在请求头和响应头中设置一些信息和想要执行的动作,这样,对方在收到信息后,就可以知道你是谁,你想干什么
常见的HTTP响应头有:
1
2
3
4
5
6
7
8
9Content-Type:表示该响应内容的类型,例如text/html,image/jpeg ;
Content-Length:表示该响应内容的长度(字节数);
Content-Encoding:表示该响应压缩算法,例如gzip ;
Cache-Control:指示客户端应如何缓存,例如max-age=300表示可以最多缓存300秒 ;
Set-Cookie: 告诉浏览器为当前页面所在的域设置cookie ;响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 --- 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
状态码大全:https://cloud.tencent.com/developer/chapter/13553
关于响应状态码,我们先主要认识三个状态码,其余的等后期用到了再去掌握:
- 200 ok 客户端请求成功
- 404 Not Found 请求资源不存在
- 500 Internal Server Error 服务端发生不可预期的错误
2.内嵌Tomcat
问题:为什么我们之前书写的SpringBoot入门程序中,并没有把程序部署到Tomcat的webapps目录下,也可以运行呢?
因为在我们的SpringBoot中,引入了web运行环境(也就是引入spring-boot-starter-web起步依赖),其内部已经集成了内置的Tomcat服务器。
我们可以通过IDEA开发工具右侧的maven面板中,就可以看到当前工程引入的依赖。其中已经将Tomcat的相关依赖传递下来了,也就是说在SpringBoot中可以直接使用Tomcat服务器。
当我们运行SpringBoot的引导类时(运行main方法),就会看到命令行输出的日志,其中占用8080端口的就是Tomcat。
3.请求响应
请求
简单参数
简单参数:在向服务器发起请求时,向服务器传递的是一些普通的请求数据。
我们在这里讲解两种方式:
原始方式
在原始的Web程序当中,需要通过Servlet中提供的API:HttpServletRequest(请求对象),获取请求的相关信息。比如获取请求参数:
Tomcat接收到http请求时:把请求的相关信息封装到HttpServletRequest对象中
在Controller中,我们要想获取Request对象,可以直接在方法的形参中声明 HttpServletRequest 对象。然后就可以通过该对象来获取请求信息:
1 | //根据指定的参数名获取请求参数的数据值 |
1 |
|
以上这种方式,我们仅做了解。(在以后的开发中不会使用到)
SpringBoot方式
在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
1 |
|
不论是GET请求还是POST请求,对于简单参数来讲,只要保证==请求参数名和Controller方法中的形参名保持一致==,就可以获取到请求参数中的数据值。
@RequestParam
@RequestParam在Spring
MVC中用于从HTTP请求中提取参数,并绑定到控制器方法的参数上。无论是在GET请求还是POST请求中,@RequestParam的基本功能都是相似的,但根据请求类型的不同,它的使用方式和目的可能有所不同。
在GET请求中:
在GET请求中,参数通常附加在URL的查询字符串上。@RequestParam用于从查询字符串中提取参数。例如,对于URL
http://example.com/search?keyword=spring,你可以使用@RequestParam来获取keyword参数的值。
1 |
|
在这个例子中,当GET请求发送到/search路径时,Spring
MVC会自动从查询字符串中提取keyword参数,并将其值绑定到search方法的keyword参数上。
在POST请求中:
在POST请求中,参数通常包含在请求体中,但@RequestParam也可以用于从URL的查询字符串中提取参数,如果参数是以这种方式传递的话。然而,更常见的是使用@RequestBody来解析请求体中的参数,尤其是当参数是复杂类型(如JSON对象)时。
但是,如果POST请求的参数是以application/x-www-form-urlencoded格式编码的(即表单数据),则可以使用@RequestParam来提取这些参数。这种情况下,参数会像GET请求中的查询字符串一样被编码,并附加在请求体中。
1 |
|
在这个例子中,当POST请求发送到/login路径时,并且请求体中包含以application/x-www-form-urlencoded格式编码的username和password参数时,Spring
MVC会自动提取这些参数的值,并将它们绑定到login方法的相应参数上。
总的来说,@RequestParam在GET请求中主要用于从URL查询字符串中提取参数,而在POST请求中则可以用于从请求体或URL查询字符串中提取以application/x-www-form-urlencoded格式编码的参数。然而,在处理POST请求中的复杂数据类型时,更常见的是使用@RequestBody注解。
如果方法形参名称与请求参数名称不一致,运行不会报错。 controller方法中的username值为:null,age值为20
对于简单参数来讲,请求参数名和controller方法中的形参名不一致时,无法接收到请求数据
解决方法:在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。
1 |
|
注意:
@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错
如果该参数是可选的,可以将required属性设置为false
1 |
|
设置默认值
可以通过@RequestParam设置默认值
1 |
|
实体参数
在使用简单参数做为数据传递方式时,前端传递了多少个请求参数,后端controller方法中的形参就要书写多少个。如果请求参数比较多,通过上述的方式一个参数一个参数的接收,会比较繁琐。
此时,我们可以考虑将请求参数封装到一个实体类对象中。 要想完成数据封装,需要遵守如下规则:请求参数名与实体类的属性名相同
简单实体对象
定义POJO实体类:
1 | public class User { |
Controller方法:
1 |
|
- 参数名和实体类属性名不一致时,对应属性是null
复杂实体对象
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
- User类中有一个Address类型的属性(Address是一个实体类)
复杂实体对象的封装,需要遵守如下规则:
- 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。
定义POJO实体类:
- Address实体类
1 | public class Address { |
- User实体类
1 | public class User { |
Controller方法:
1 |
|
需要传递的:
name
age
address.province
address.city
数组集合参数的使用场景:在HTML的表单中,有一个表单项是支持多选的(复选框),可以提交选择的多个值。
多个值是怎么提交的呢?其实多个值也是一个一个的提交。是参数名一样,但参数值不同提交多个 。
在前端请求时,有两种传递形式:
方式一:
http://localhost:8080/arrayParam?hobby=game&hobby=java
方式二:http://localhost:8080/arrayParam?hobby=game,java
后端程序接收上述多个值的方式有两种:
- 数组
- 集合
数组参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
Controller方法:
1 |
|
集合参数
集合参数:请求参数名与形参集合对象名相同且请求参数为多个,@RequestParam 绑定参数关系
- 默认情况下,请求中参数名相同的多个值,是封装到数组。如果要封装到集合,要使用@RequestParam绑定参数关系
Controller方法:
1 |
|
日期参数
上述演示的都是一些普通的参数,在一些特殊的需求中,可能会涉及到日期类型数据的封装。
因为日期的格式多种多样(如:2022-12-12 10:05:45 、2022/12/12 10:05:45),那么对于日期类型的参数在进行封装的时候,需要通过@DateTimeFormat注解,以及其pattern属性来设置日期的格式。
http://localhost:8080/dateParam?updateTime=2022-12-12 10:05:45
- @DateTimeFormat注解的pattern属性中指定了哪种日期格式,前端的日期参数就必须按照指定的格式传递。
- 后端controller方法中,需要使用Date类型或LocalDateTime类型,来封装传递的参数。
Controller方法:
1 |
|
JSON参数
在学习前端技术时,我们有讲到过JSON,而在前后端进行交互时,如果是比较复杂的参数,前后端通过会使用JSON格式的数据进行传输。 (JSON是开发中最常用的前后端数据交互方式)
我们学习JSON格式参数,主要从以下两个方面着手:
- Postman在发送请求时,如何传递json格式的请求参数
- 在服务端的controller方法中,如何接收json格式的请求参数
Postman发送JSON格式数据:
服务端Controller方法接收JSON格式数据:
传递json格式的参数,在Controller中会使用实体类进行封装。
封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
@RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
实体类:Address
1 | public class Address { |
实体类:User
1 | public class User { |
Controller方法:
1 |
|
路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
1 | http://localhost:8080/user/1 |
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
学习路径参数呢,主要掌握在后端的controller方法中,如何接收路径参数。
路径参数:
前端:通过请求URL直接传递参数
http://localhost:8080/path/100后端:使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
Controller方法:
1 |
|
传递多个路径参数:
URL:http://localhost:880/path/1/ITCAST
Controller方法:
1 |
|
响应
@ResponseBody
在我们前面所编写的controller方法中,都已经设置了响应数据。
1 | return "Hello World" //响应给浏览器的结果 |
controller方法中的return的结果,怎么就可以响应给浏览器呢?
答案:使用@ResponseBody注解
@ResponseBody注解:
- 类型:方法注解、类注解
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
但是在我们所书写的Controller中,只在类上添加了@RestController注解、方法添加了@RequestMapping注解,并没有使用@ResponseBody注解,怎么给浏览器响应呢?
1 |
|
原因:在类上添加的@RestController注解,是一个组合注解。
@RestController=@Controller+@ResponseBody
@RestController源码:
1 | //元注解(修饰注解的注解) |
结论:在类上添加@RestController就相当于添加了@ResponseBody注解。
- 类上有@RestController注解或@ResponseBody注解时:表示当前类下所有的方法返回值做为响应数据
- 方法的返回值,如果是一个POJO对象或集合时,会先转换为JSON格式,在响应给浏览器
下面我们来测试下响应数据:
1 |
|
在服务端响应了一个对象或者集合,那私前端获取到的数据是什么样子的呢?
1 | { |
1 | [ |
统一响应结果
我们在前面所编写的这些Controller方法中,返回值各种各样,没有任何的规范。
在真实的项目开发中,无论是哪种方法,我们都会定义一个统一的返回结果。方案如下:
统一的返回结果使用类来描述,在这个结果中包含:
响应状态码:当前请求是成功,还是失败
状态码信息:给页面的提示信息
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息。代码如下:
1 | public class Result { |
改造Controller:
1 |
|
使用Postman测试:
在服务端响应了一个对象或者集合,那私前端获取到的数据是什么样子的呢?测试效果如下:
1 | { |
1 | { |
分层解耦
三层架构
在我们进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
其实我们之前的程序的处理逻辑呢,从组成上看可以分为三个部分:
- 数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
- 逻辑处理:负责业务逻辑处理的代码。
- 请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
按照上述的三个组成部分,在我们项目开发中呢,可以将代码分为三层:
- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
基于三层架构的程序执行流程:
- 前端发起的请求,由Controller层接收(Controller响应数据给前端)
- Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
- Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
- Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
思考:按照三层架构的思想,如何要对业务逻辑(Service层)进行变更,会影响到Controller层和Dao层吗?
答案:不会影响。 (程序的扩展性、维护性变得更好了)
代码拆分
我们使用三层架构思想,来改造下之前的程序:
- 控制层包名:xxxx.controller
- 业务逻辑层包名:xxxx.service
- 数据访问层包名:xxxx.dao

控制层:接收前端发送的请求,对请求进行处理,并响应数据
1 |
|
业务逻辑层:处理具体的业务逻辑
- 业务接口
1 | //业务逻辑接口(制定业务标准) |
- 业务实现类
1 | //业务逻辑实现类(按照业务标准实现) |
数据访问层:负责数据的访问操作,包含数据的增、删、改、查
- 数据访问接口
1 | //数据访问层接口(制定标准) |
- 数据访问实现类
1 | //数据访问实现类 |
三层架构的好处:
- 复用性强
- 便于维护
- 利用扩展
分层解耦
刚才我们学习过程序分层思想了,接下来呢,我们来学习下程序的解耦思想。
解耦:解除耦合。
耦合问题
解软件开发涉及到的两个概念:内聚和耦合。
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
程序中高内聚的体现:
- EmpServiceA类中只编写了和员工相关的逻辑处理代码
程序中耦合代码的体现:
- 把业务类变为EmpServiceB时,需要修改controller层中的代码
高内聚、低耦合的目的是使程序模块的可重用性、移植性大大增强。
解耦思路
之前我们在编写代码时,需要什么对象,就直接new一个就可以了。 这种做法呢,层与层之间代码就耦合了,当service层的实现变了之后, 我们还需要修改controller层的代码。
那应该怎么解耦呢?
首先不能在EmpController中使用new对象。
此时,就存在另一个问题了,不能new,就意味着没有业务层对象(程序运行就报错),怎么办呢?
- 我们的解决思路是:
- 提供一个容器,容器中存储一些对象(例:EmpService对象)
- controller程序从容器中获取EmpService类型的对象
- 我们的解决思路是:
我们想要实现上述解耦操作,就涉及到Spring中的两个核心概念:
控制反转: Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转。
对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
依赖注入: Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
程序运行时需要某个资源,此时容器就为其提供这个资源。
例:EmpController程序运行时需要EmpService对象,Spring容器就为其提供并注入EmpService对象
IOC容器中创建、管理的对象,称之为:bean对象
IOC&DI
上面我们引出了Spring中IOC和DI的基本概念,下面我们就来具体学习下IOC和DI的代码实现。
入门
- 思路:
- 删除Controller层、Service层中new对象的代码
- Service层及Dao层的实现类,交给IOC容器管理
- 为Controller及Service注入运行时依赖的对象
- Controller程序中注入依赖的Service层对象
- Service程序中注入依赖的Dao层对象
第1步:删除Controller层、Service层中new对象的代码
第2步:Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
第3步:为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象
完整的三层代码:
- Controller层:
1 |
|
- Service层:
1 | //将当前对象交给IOC容器管理,成为IOC容器的bean |
- Dao层:
1 | //将当前对象交给IOC容器管理,成为IOC容器的bean |
bean的声明
前面我们提到IOC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对象。IOC容器创建的对象称为bean对象。
在之前的入门案例中,要把某个对象交给IOC容器管理,需要在类上添加一个注解:@Component
而Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
- @Controller (标注在控制层类上)
- @Service (标注在业务层类上)
- @Repository (标注在数据访问层类上)
修改入门案例代码:
- Controller层:
1 | //@RestController = @Controller + @ResponseBody |
- Service层:
1 |
|
Dao层:
1 |
|
要把某个对象交给IOC容器管理,需要在对应的类上加上如下注解之一:
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少) |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
在IOC容器中,每一个Bean都有一个属于自己的名字,可以通过注解的value属性指定bean的名字。如果没有指定,默认为类名首字母小写。
注意事项:
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
- 使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
组件扫描
使用前面学习的四个注解声明的bean,不一定会生效(原因:bean想要生效,还需要被组件扫描)
- 使用四大注解声明的bean,要想生效,还需要被组件扫描注解@ComponentScan扫描
@ComponentScan注解虽然没有显式配置,但是实际上已经包含在了引导类声明注解 @SpringBootApplication 中,默认扫描的范围是SpringBoot启动类所在包及其子包。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public SpringBootApplication {...}
解决方案:手动添加@ComponentScan注解,指定要扫描的包 (==仅做了解,不推荐==)
1
2
3
public class ManagementUserApplication {...}
推荐做法(如下图):
- 将我们定义的controller,service,dao这些包呢,都放在引导类所在包com.nicccce的子包下,这样我们定义的bean就会被自动的扫描到
DI细节
依赖注入,是指IOC容器要为应用程序去提供运行时所依赖的资源,而资源指的就是对象。
在入门程序案例中,我们使用了@Autowired这个注解,完成了依赖注入的操作,而这个Autowired翻译过来叫:自动装配。
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
入门程序举例:在EmpController运行的时候,就要到IOC容器当中去查找EmpService这个类型的对象,而我们的IOC容器中刚好有一个EmpService这个类型的对象,所以就找到了这个类型的对象完成注入操作。
那如果在IOC容器中,存在多个相同类型的bean对象,程序运行会报错
Spring提供了以下几种解决方案:
@Primary
@Qualifier
@Resource
使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
1 | //让当前bean生效 |
使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。
- @Qualifier注解不能单独使用,必须配合@Autowired使用
1 |
|
使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
1 |
|
@Autowird 与 @Resource的区别
- @Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired 默认是按照类型注入,而@Resource是按照名称注入
MySQL
数据模型
关系型数据库(RDBMS)
概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
而所谓二维表,指的是由行和列组成的表。
二维表的优点:
使用表存储数据,格式统一,便于维护
使用SQL语言操作,标准统一,使用方便,可用于复杂查询
我们之前提到的MySQL、Oracle、DB2、SQLServer这些都是属于关系型数据库,里面都是基于二维表存储数据的。
基于二维表存储数据的数据库就成为关系型数据库,不是基于二维表存储数据的数据库,就是非关系型数据库(比如Redis,就属于非关系型数据库)。
2). 数据模型
MySQL是关系型数据库,是基于二维表进行数据存储的,具体的结构图下:

- 通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库
- 使用MySQL客户端,向数据库管理系统发送一条SQL语句,由数据库管理系统根据SQL语句指令去操作数据库中的表结构及数据
- 一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
SQL语句
SQL:结构化查询语言。一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
1 | mysql> create |
2、SQL语句可以使用空格/缩进来增强语句的可读性。
3、MySQL数据库的SQL语句不区分大小写。
4、注释:
- 单行注释:-- 注释内容 或 # 注释内容(MySQL特有)
- 多行注释: /* 注释内容 */
语句分类
SQL语句根据其功能被分为四大类:DDL、DML、DQL、DCL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
数据定义-DDL
DDL英文全称是Data Definition Language(数据定义语言),用来定义数据库对象(数据库、表)。
数据库操作
DDL中数据库的常见操作:查询、创建、使用、删除。
查询数据库
查询所有数据库:
1 | show databases; |
命令行中执行效果如下:
1 | +--------------------+ |
查询当前数据库:
1 | select database(); |
命令行中执行效果如果:
1 | mysql> -- 当前没有使用任何数据库 |
创建数据库
语法:
1 | create database [ if not exists ] 数据库名; |
案例: 创建一个itcast数据库。
1 | create database itcast; |
在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错。
可以使用if not exists来避免这个问题
1 | -- 数据库不存在,则创建该数据库;如果存在则不创建 |
使用数据库
语法:
1 | use 数据库名 ; |
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则不能操作。
删除数据库
语法:
1 | drop database [ if exists ] 数据库名 ; |
如果删除一个不存在的数据库,将会报错。
可以加上参数 if exists ,如果数据库存在,再执行删除,否则不执行删除。
说明:上述语法中的database,也可以替换成 schema
- 如:create schema db01;
- 如:show schemas;
表结构操作
关于表结构的操作也是包含四个部分:创建表、查询表、修改表、删除表。
创建
1 | create table 表名( |
注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号
- 示例:
1 | create table tb_user ( |
约束
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。
作用:就是来保证数据库当中数据的正确性、有效性和完整性。
在MySQL数据库当中,提供了以下5种约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
- 示例:
1 | create table tb_user ( |
主键自增:auto_increment
- 每次插入新的行记录时,数据库自动生成id字段(主键)下的值
- 具有auto_increment的数据列是一个正数序列开始增长(从1开始自增)
数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
- MySQL中没有布尔类型,会用tinyint来表示,其中0表示false,1表示true
数值类型
| 类型 |
大小 /byte |
有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 | 备注 |
|---|---|---|---|---|---|
| tinyint | 1 | (-128,127) | (0,255) | 小整数值 | |
| smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 | |
| mediumint | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 | |
| int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 | |
| bigint | 8 | (-263,263-1) | (0,2^64-1) | 极大整数值 | |
| float | 4 | (-3.402823466 E+38,3.402823466351 E+38) |
0 和 (1.175494351 E-38,3.402823466 E+38) |
单精度浮点数值 | float(5,2):5表示整个数字长度,2 表示小数位个数 |
| double | 8 |
(-1.7976931348623157 E+308, 1.7976931348623157 E+308) |
0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) |
双精度浮点数值 | double(5,2):5表示整个数字长度,2 表示小数位个数 |
| decimal | 字符串形式储存,依赖于M(精度)和D(标度)的值 | 小数值(精度更高) | decimal(5,2):5表示整个数字长度,2 表示小数位个数 | ||
1 | 示例: |
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0-255 bytes | 定长字符串 |
| varchar | 0-65535 bytes | 变长字符串 |
| tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 |
| tinytext | 0-255 bytes | 短文本字符串 |
| blob | 0-65 535 bytes | 二进制形式的长文本数据 |
| text | 0-65 535 bytes | 长文本数据 |
| mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16 777 215 bytes | 中等长度文本数据 |
| longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| longtext | 0-4 294 967 295 bytes | 极大文本数据 |
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。
而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
1 | 示例: |
日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
1 | 示例: |
查询
关于表结构的查询操作,工作中一般都是直接基于图形化界面操作。
查询指定表的建表语句
1 | show create table 表名 ; |
修改
关于表结构的修改操作,工作中一般都是直接基于图形化界面操作。
添加字段
1 | alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]; |
案例: 为tb_emp表添加字段qq,字段类型为 varchar(11)
1 | alter table tb_emp add qq varchar(11) comment 'QQ号码'; |
修改数据类型
1 | alter table 表名 modify 字段名 新数据类型(长度); |
1 | alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束]; |
案例:修改qq字段的字段类型,将其长度由11修改为13
1 | alter table tb_emp modify qq varchar(13) comment 'QQ号码'; |
案例:修改qq字段名为 qq_num,字段类型varchar(13)
1 | alter table tb_emp change qq qq_num varchar(13) comment 'QQ号码'; |
删除字段
1 | alter table 表名 drop 字段名; |
案例:删除tb_emp表中的qq_num字段
1 | alter table tb_emp drop qq_num; |
修改表名
1 | rename table 表名 to 新表名; |
案例:将当前的tb_emp表的表名修改为emp
1 | rename table tb_emp to emp; |
删除
关于表结构的删除操作,工作中一般都是直接基于图形化界面操作。
删除表语法:
1 | drop table [ if exists ] 表名; |
if exists :只有表名存在时才会删除该表,表名不存在,则不执行删除操作(如果不加该参数项,删除一张不存在的表,执行将会报错)。
案例:如果tb_emp表存在,则删除tb_emp表
1 | drop table if exists tb_emp; -- 在删除表时,表中的全部数据也会被删除。 |
数据操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
增加(insert)
insert语法:
向指定字段添加数据
1
insert into 表名 (字段名1, 字段名2) values (值1, 值2);
全部字段添加数据
1
insert into 表名 values (值1, 值2, ...);
批量添加数据(指定字段)
1
insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);
批量添加数据(全部字段)
1
insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);
案例1:向tb_emp表的username、name、gender字段插入数据
1 | -- 因为设计表时create_time, update_time两个字段不能为NULL,所以也做为要插入的字段 |
案例2:向tb_emp表的所有字段插入数据
1 | insert into tb_emp(id, username, password, name, gender, image, job, entrydate, create_time, update_time) |
案例3:批量向tb_emp表的username、name、gender字段插入数据
1 | insert into tb_emp(username, name, gender, create_time, update_time) |
注意:
插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
字符串和日期型数据应该包含在引号中。
插入的数据大小,应该在字段的规定范围内。
修改(update)
update语法:
1 | update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ; |
案例1:将tb_emp表中id为1的员工,姓名name字段更新为'张三'
1 | update tb_emp set name='张三',update_time=now() where id=1; |
案例2:将tb_emp表的所有员工入职日期更新为'2010-01-01'
1 | update tb_emp set entrydate='2010-01-01',update_time=now(); |
注意:
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
删除(delete)
delete语法:
1 | delete from 表名 [where 条件] ; |
案例1:删除tb_emp表中id为1的员工
1 | delete from tb_emp where id = 1; |
案例2:删除tb_emp表中所有员工
1 | delete from tb_emp; |
注意:
• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
• DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
• 当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
数据查询-DQL
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询关键字:SELECT
语法
DQL查询语句,语法结构如下:
1 | select |
测试数据:
1 | create database db02; -- 创建数据库 |
基本查询
在基本查询的DQL语句中,不带任何的查询条件,语法如下:
查询多个字段
1
select 字段1, 字段2, 字段3 from 表名;
查询所有字段(通配符)
1
select * from 表名;
设置别名
1
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;
去除重复记录
1
select distinct 字段列表 from 表名;
案例:查询所有员工的 name,entrydate,并起别名(姓名、入职日期)
1 | -- 方式1: |
案例:查询已有的员工关联了哪几种职位(不要重复)
1 | select distinct job from tb_emp; |
条件查询
语法:
1 | select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件 |
在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between ... and ... | 在某个范围之内(含最小、最大值) |
| in(...) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 || | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
案例:查询 姓名 为 杨逍 的员工
1 | select * |
案例:查询 没有分配职位 的员工信息
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
案例:查询 有职位 的员工信息
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
案例:查询 密码不等于 '123456' 的员工信息
1 | -- 方式1: |
案例:查询 入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息
1 | -- 方式1: |
案例:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
1 | -- 方式1:使用or连接多个条件 |
案例:查询 姓名 为两个字的员工信息
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
案例:查询 姓 '张' 的员工信息
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
聚合函数
之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
1 | select 聚合函数(字段列表) from 表名 ; |
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 | |
|---|---|---|
| count | 按照列去统计有多少行数据。 | |
| max | 计算指定列的最大值 | |
| min | 计算指定列的最小值 | |
| avg | 计算指定列的平均值 | |
| sum | 计算指定列的数值和,如果不是数值类型,那么计算结果为0 |
在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
count
1 | # count(字段) |
- min
1 | -- 统计该企业最早入职的员工 |
- max
1 | -- 统计该企业最迟入职的员工 |
- avg
1 | -- 统计该企业员工 ID 的平均值 |
- sum
1 | -- 统计该企业员工的 ID 之和 |
分组查询
按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
1 | select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]; |
注意事项:
• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
• 执行顺序:where > 聚合函数 > having
案例1:根据性别分组 , 统计男性和女性员工的数量
1 | select gender, count(*) |
案例2:查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
1 | select job, count(*) |
where与having区别
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
1 | select 字段列表 |
排序方式:
ASC :升序(默认值)
DESC:降序
案例1:根据入职时间, 对员工进行升序排序
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
注意事项:如果是升序, 可以不指定排序方式ASC
案例2:根据入职时间,对员工进行降序排序
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:
1 | select 字段列表 from 表名 limit 起始索引, 查询记录数 ; |
从起始索引0开始查询员工数据, 每页展示5条记录
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
查询 第1页 员工数据, 每页展示5条记录
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
查询 第2页
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
查询 第3页
1 | select id, username, password, name, gender, image, job, entrydate, create_time, update_time |
注意事项:
起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数
if
员工性别统计:
1 | -- if(条件表达式, true取值 , false取值) |
if(表达式, tvalue, fvalue) :当表达式为true时,取值tvalue;当表达式为false时,取值fvalue
case
员工职位统计:
1 | -- case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else result end |
case 表达式 when 值1 then 结果1 [when 值2 then 结果2 ...] [else result]
ECharts报表组件库
多表设计
示例数据:
新增部门表:
1 | # 建议:创建新的数据库(多表设计存放在新数据库下) |
员工表:添加归属部门字段
1 | -- 员工表 |
测试数据:
1 | -- 部门表测试数据 |
一对多
外键约束
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
关键字:foreign key
外键约束的语法:
1 | -- 创建表时指定 |
示例:通过SQL语句操作
1 | -- 修改表: 添加外键约束,使部门表关联员工表的部门 |
当我们添加外键约束时,我们得保证当前数据库表中的数据是完整的。 所以,我们需要将之前删除掉的数据再添加回来。
当我们添加了外键之后,再删除ID为1的部门,就会发现,此时数据库报错了,不允许删除。
外键约束(foreign key):保证了数据的完整性和一致性。
物理外键和逻辑外键
- 物理外键
- 概念:使用foreign key定义外键关联另外一张表。
- 缺点:
- 影响增、删、改的效率(需要检查外键关系)。
- 仅用于单节点数据库,不适用与分布式、集群场景。
- 容易引发数据库的死锁问题,消耗性能。
- 逻辑外键
- 概念:在业务层逻辑中,解决外键关联。
- 通过逻辑外键,就可以很方便的解决上述问题。
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
一对一
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景: 用户表(基本信息+身份信息)
基本信息:用户的ID、姓名、性别、手机号、学历
- 身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间)
如果在业务系统当中,对用户的基本信息查询频率特别的高,但是对于用户的身份信息查询频率很低,此时出于提高查询效率的考虑,我就可以将这张大表拆分成两张小表,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。他们两者之间一对一的关系,一个用户只能对应一个身份证,而一个身份证也只能关联一个用户。
那么在数据库层面怎么去体现上述两者之间是一对一的关系呢?
其实一对一我们可以看成一种特殊的一对多。一对多我们是怎么设计表关系的?是不是在多的一方添加外键。同样我们也可以通过外键来体现一对一之间的关系,我们只需要在任意一方来添加一个外键就可以了。
如:id和user_id
一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
SQL脚本:
1 | -- 用户基本信息表 |
多对多
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
案例:学生与课程的关系
- 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
- 实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
SQL脚本:
1 | -- 学生表 |
多表查询
示例主句
SQL脚本:
1 | #创建新的数据库 |
基本操作
- 多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2;
查询用户表和部门表中的数据:
1 | select * from tb_emp , tb_dept; |
此时,我们看到查询结果中包含了大量的结果集,总共85条记录,而这其实就是员工表所有的记录(17行)与部门表所有记录(5行)的所有组合情况,这种现象称之为笛卡尔积。
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况。
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据
在SQL语句中,如何去除无效的笛卡尔积呢?只需要给多表查询加上连接查询的条件即可。
1 | select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ; |
由于id为17的员工,没有dept_id字段值,所以在多表查询时,根据连接查询的条件并没有查询到。
多表查询可以分为:
连接查询
- 内连接:相当于查询A、B交集部分数据
外连接
左外连接:查询左表所有数据(包括两张表交集部分数据)
右外连接:查询右表所有数据(包括两张表交集部分数据)
子查询
内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:
隐式内连接
显式内连接
隐式内连接语法:
1 | select 字段列表 from 表1 , 表2 where 条件 ... ; |
显式内连接语法:
1 | select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ; |
案例:查询员工的姓名及所属的部门名称
- 隐式内连接实现
1 | select tb_emp.name , tb_dept.name -- 分别查询两张表中的数据 |
- 显式内连接实现
1 | select tb_emp.name , tb_dept.name |
必须加上表名,不加会报错
1 | select name |
多表查询时给表起别名:
tableA as 别名1 , tableB as 别名2 ;
tableA 别名1 , tableB 别名2 ;
使用了别名的多表查询:
1 | select e.name, d.name from tb_emp e , tb_dept d where e.dept_id = d.id; |
- 一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:
1 | select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ; |
- 左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接语法结构:
1 | select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ; |
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
查询员工表中所有员工的姓名, 和对应的部门名称
1 | -- 左外连接:以left join关键字左边的表为主表,查询主表中所有数据,以及和主表匹配的右边表中的数据 |
- 查询部门表中所有部门的名称, 和对应的员工名称
1 | -- 右外连接 |
- 左外连接和右外连接是可以相互替换的,只需要调整连接查询时SQL语句中表的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
子查询
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
1 | SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... ); |
子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
根据子查询结果的不同分为:
标量子查询(子查询结果为单个值[一行一列])
列子查询(子查询结果为一列,但可以是多行)
行子查询(子查询结果为一行,但可以是多列)
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:
- where之后
- from之后
- select之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: = <> > >= < <=
案例:查询在 "方东白" 入职之后的员工信息
可以将需求分解为两步:
- 查询 方东白 的入职日期
- 查询 指定入职日期之后入职的员工信息
1 | -- 1.查询"方东白"的入职日期 |
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
案例:查询"教研部"和"咨询部"的所有员工信息
分解为以下两步:
- 查询 "销售部" 和 "市场部" 的部门ID
- 根据部门ID, 查询员工信息
1 | -- 1.查询"销售部"和"市场部"的部门ID |
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:查询与"韦一笑"的入职日期及职位都相同的员工信息
可以拆解为两步进行:
- 查询 "韦一笑" 的入职日期 及 职位
- 查询与"韦一笑"的入职日期及职位相同的员工信息
1 | -- 查询"韦一笑"的入职日期 及 职位 |
表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询,一般放在from之后。
案例:查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分解为两步执行:
- 查询入职日期是 "2006-01-01" 之后的员工信息
- 基于查询到的员工信息,在查询对应的部门信息
1 | select * from emp where entrydate > '2006-01-01'; |
事务
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
场景:学工部整个部门解散了,该部门及部门下的员工都需要删除了。
操作:
1
2
3
4
5-- 删除学工部
delete from dept where id = 1; -- 删除成功
-- 删除学工部的员工
delete from emp where dept_id = 1; -- 删除失败(操作过程中出现错误:造成删除没有成功)问题:如果删除部门成功了,而删除该部门的员工时失败了,此时就造成了数据的不一致。
要解决上述的问题,就需要通过数据库中的事务来解决。
操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交,即两句话是两个事务)
- 手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
使用事务控制删除部门和删除该部门下的员工的操作:
1 | -- 开启事务 |
- 上述的这组SQL语句,如果如果执行成功,则提交事务
1 | -- 提交事务 (成功时执行) |
- 上述的这组SQL语句,如果如果执行失败,则回滚事务
1 | -- 回滚事务 (出错时执行) |
特性
事务的四大特性简称为:ACID
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
- 隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。
- 持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
索引
索引(index):是帮助数据库高效获取数据的数据结构 。
- 简单来讲,就是使用索引可以提高查询的效率。
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
树结构:
二叉查找树:左边的子节点比父节点小,右边的子节点比父节点大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31graph TB
A((36))
B((22))
C((19))
D((17))
E((20))
F((33))
G((23))
H((34))
I((48))
J((45))
K((40))
L((46))
M((53))
N((50))
O((70))
A-->B
B-->C
C-->D
C-->E
B-->F
F-->G
F-->H
A-->I
I-->J
J-->K
J-->L
I-->M
M-->N
M-->O当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15graph TB
A((36))
B((22))
C((19))
D((17))
E((20))
F((33))
H((34))
A-->H
H-->F
F-->B
B-->E
E-->C
C-->D可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)
但是在Mysql数据库中并没有使用二叉搜索数或二叉平衡数或红黑树来作为索引的结构。
思考:采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。
下面我们来看看B+Tree(多路平衡搜索树)结构中如何避免这个问题:
B+Tree结构:
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
拓展:
非叶子节点都是由key+指针域组成的,一个key占8字节,一个指针占6字节,而一个节点总共容量是16KB,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6)=1170个元素。
- 查看mysql索引节点大小:show global status like 'innodb_page_size'; -- 节点大小:16384
当根节点中可以存储1170个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储1170个元素,那么第二层即第二次IO的时候就会找到数据大概是:1170*1170=135W。也就是说B+Tree数据结构中只需要经历两次磁盘IO就可以找到135W条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由key+数据组成,假设key+数据总大小是1KB,而每个节点一共能存储16KB,所以一个第三层一个节点大概可以存储16个元素(即16条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是135W个元素,那么第三层总元素大小就是:135W*16结果就是2000W+的元素个数。
结合上述分析B+Tree有如下优点:
- 千万条数据,B+Tree可以控制在小于等于3的高度
- 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
语法
创建索引
1 | create [ unique ] index 索引名 on 表名 (字段名,... ) ; |
案例:为tb_emp表的name字段建立一个索引
1 | create index idx_emp_name on tb_emp(name); |
- 在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束
- 主键索引性能最高
查看索引
1 | show index from 表名; |
案例:查询 tb_emp 表的索引信息
1 | show index from tb_emp; |
删除索引
1 | drop index 索引名 on 表名; |
案例:删除 tb_emp 表中name字段的索引
1 | drop index idx_emp_name on tb_emp; |
注意事项:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引
Mybatis
什么是MyBatis?
MyBatis是一款优秀的 持久层 框架,用于简化JDBC的开发。
MyBatis本是 Apache的一个开源项目iBatis,2010年这个项目由apache迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。
官网:https://mybatis.org/mybatis-3/zh/index.html
在上面我们提到了两个词:一个是持久层,另一个是框架。
持久层:指的是就是数据访问层(dao),是用来操作数据库的。
框架:是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。在框架的基础上进行软件开发更加高效、规范、通用、可拓展。
入门程序实现
准备工作
创建springboot工程
创建springboot工程,并导入 mybatis的起步依赖、mysql的驱动包。
项目工程创建完成后,自动在pom.xml文件中,导入Mybatis依赖和MySQL驱动依赖
1 | <!-- 仅供参考:只粘贴了pom.xml中部分内容 --> |
创建实体类
创建用户表user,并创建对应的实体类User。
- 用户表:
1 | -- 用户表 |
实体类(PO)
- 实体类的属性名与表中的字段名一一对应。
1 | public class User { |
配置Mybatis
在springboot项目中,可以编写application.properties文件,配置数据库连接信息。我们要连接数据库,就需要配置数据库连接的基本信息,包括:driver-class-name、url 、username,password。
application.properties:
1 | #驱动类名称 |
上述的配置 全部都是 spring.datasource.xxxx 开头。
编写SQL语句
在创建出来的springboot工程中,在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper ,这是一个持久层接口(Mybatis的持久层接口规范一般都叫 XxxMapper)。
UserMapper:
1 | import com.nicccce.pojo.User; |
@Mapper注解:表示是mybatis中的Mapper接口
- 程序运行时:框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
单元测试
在创建出来的SpringBoot工程中,在src下的test目录下,已经自动帮我们创建好了测试类 ,并且在测试类上已经添加了注解 @SpringBootTest,代表该测试类已经与SpringBoot整合。
该测试类在运行时,会自动通过引导类加载Spring的环境(IOC容器)。我们要测试那个bean对象,就可以直接通过@Autowired注解直接将其注入进行,然后就可以测试了。
测试类代码如下:
1 |
|
运行结果:
2
3
4
5
6
User{id=2, name='金毛狮王', age=45, gender=1, phone='18800000001'}
User{id=3, name='青翼蝠王', age=38, gender=1, phone='18800000002'}
User{id=4, name='紫衫龙王', age=42, gender=2, phone='18800000003'}
User{id=5, name='光明左使', age=37, gender=1, phone='18800000004'}
User{id=6, name='光明右使', age=48, gender=1, phone='18800000005'}
JDBC
java语言操作数据库,只能通过一种方式:使用sun公司提供的 JDBC 规范。
Mybatis框架,就是对原始的JDBC程序的封装。
JDBC: ( Java DataBase Connectivity ),就是使用Java语言操作关系型数据库的一套API。
本质:
sun公司官方定义的一套操作所有关系型数据库的规范,即接口。
各个数据库厂商去实现这套接口,提供数据库驱动jar包。
我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类。
代码
下面我们看看原始的JDBC程序是如何操作数据库的。操作步骤如下:
- 注册驱动
- 获取连接对象
- 执行SQL语句,返回执行结果
- 处理执行结果
- 释放资源
在pom.xml文件中已引入MySQL驱动依赖,我们直接编写JDBC代码即可
JDBC具体代码实现:
1 | import com.nicccce.pojo.User; |
DriverManager(类):数据库驱动管理类。
作用:
注册驱动
创建java代码和数据库之间的连接,即获取Connection对象
Connection(接口):建立数据库连接的对象
- 作用:用于建立java程序和数据库之间的连接
Statement(接口): 数据库操作对象(执行SQL语句的对象)。
- 作用:用于向数据库发送sql语句
ResultSet(接口):结果集对象(一张虚拟表)
- 作用:sql查询语句的执行结果会封装在ResultSet中
通过上述代码,我们看到直接基于JDBC程序来操作数据库,代码实现非常繁琐,所以在项目开发中,我们很少使用。 在项目开发中,通常会使用Mybatis这类的高级技术来操作数据库,从而简化数据库操作、提高开发效率。
问题分析
原始的JDBC程序,存在以下几点问题:
- 数据库链接的四要素(驱动、链接、用户名、密码)全部硬编码在java代码中
- 查询结果的解析及封装非常繁琐
- 每一次查询数据库都需要获取连接,操作完毕后释放连接, 资源浪费, 性能降低
技术对比
分析了JDBC的缺点之后,我们再来看一下在mybatis中,是如何解决这些问题的:
数据库连接四要素(驱动、链接、用户名、密码),都配置在springboot默认的配置文件 application.properties中
查询结果的解析及封装,由mybatis自动完成映射封装,我们无需关注
在mybatis中使用了数据库连接池技术,从而避免了频繁的创建连接、销毁连接而带来的资源浪费。
使用SpringBoot+Mybatis的方式操作数据库,能够提升开发效率、降低资源浪费
而对于Mybatis来说,我们在开发持久层程序操作数据库时,需要重点关注以下两个方面:
application.properties
1
2
3
4
5
6
7
8#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=1234Mapper接口(编写SQL语句)
1
2
3
4
5
public interface UserMapper {
public List<User> list();
}
数据库连接池
mybatis中,使用了数据库连接池技术,避免频繁的创建连接、销毁连接而带来的资源浪费。
没有使用数据库连接池:
- 客户端执行SQL语句:要先创建一个新的连接对象,然后执行SQL语句,SQL语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。
数据库连接池是个容器,负责分配、管理数据库连接(Connection)
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 客户端在执行SQL时,先从连接池中获取一个Connection对象,然后在执行SQL语句,SQL语句执行完之后,释放Connection时就会把Connection对象归还给连接池(Connection对象可以复用)
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
- 客户端获取到Connection对象了,但是Connection对象并没有去访问数据库(处于空闲),数据库连接池发现Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动释放掉这个连接对象
数据库连接池的好处:
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
产品
要怎么样实现数据库连接池呢?
官方(sun)提供了数据库连接池标准(javax.sql.DataSource接口)
功能:获取连接
1
public Connection getConnection() throws SQLException;
第三方组织必须按照DataSource接口实现
常见的数据库连接池:
- C3P0
- DBCP
- Druid
- Hikari (springboot默认)
现在使用更多的是:Hikari、Druid (性能更优越)
Hikari(追光者) [默认的连接池]
Druid(德鲁伊)
Druid连接池是阿里巴巴开源的数据库连接池项目
功能强大,性能优秀,是Java语言最好的数据库连接池之一
如果我们想把默认的数据库连接池切换为Druid数据库连接池,只需要完成以下两步操作即可:
参考官方地址:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
- 在pom.xml文件中引入依赖
1 | <dependency> |
- 在application.properties中引入数据库连接配置
方式1:
1 | spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver |
方式2:
1 | spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver |
lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码。
通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率。
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
使用
第1步:在pom.xml文件中引入依赖
1 | <!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> |
第2步:在实体类上添加注解
1 | import lombok.Data; |
在实体类上添加了@Data注解,那么这个类在编译时期,就会生成getter/setter、equals、hashcode、toString等方法。
说明:@Data注解中不包含全参构造方法,通常在实体类上,还会添加上:全参构造、无参构造
1 | import lombok.Data; |
Lombok的注意事项:
- Lombok会在编译时,会自动生成对应的java代码
- 在使用lombok时,还需要安装一个lombok的插件(新版本的IDEA中自带)
基础操作
示例数据库表
1 | -- 部门管理 |
创建对应的实体类Emp(实体类属性采用驼峰命名)
1 |
|
准备Mapper接口:mapper.EmpMapper
1 | /*@Mapper注解:表示当前接口为mybatis中的Mapper接口 |
删除
功能:根据主键删除数据
- SQL语句
1 | -- 删除id=17的数据 |
Mybatis框架让程序员更关注于SQL语句
- 接口方法
1 |
|
@Delete注解:用于编写delete操作的SQL语句
如果mapper接口方法形参只有一个普通类型的参数,#{…} 里面的属性名可以随便写,如:#{id}、#{value}。但是建议保持名字一致。
- 测试
- 在单元测试类中通过@Autowired注解注入EmpMapper类型对象
1 |
|
日志输入
在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果。具体操作如下:
打开application.properties文件
开启mybatis的日志,并指定输出到控制台
1 | #指定mybatis输出日志的位置, 输出控制台 |
开启日志之后,我们再次运行单元测试,可以看到在控制台中,输出了以下的SQL语句信息:
1 | ==> Preparing: delete from emp where id = ? |
但是我们发现输出的SQL语句:delete from emp where id = ?,我们输入的参数16并没有在后面拼接,id的值是使用?进行占位。那这种SQL语句我们称为预编译SQL。
预编译SQL
预编译SQL有两个优势:
- 性能更高
- 更安全(防止SQL注入)
性能更高:预编译SQL,编译一次之后会将编译后的SQL语句缓存起来,后面再次执行这条语句时,不会再次编译。(只是输入的参数不同)
更安全(防止SQL注入):将敏感字进行转义,保障SQL的安全性。
SQL注入
SQL注入:是通过操作输入的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法。
由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。
用户在页面提交数据的时候人为的添加一些特殊字符,使得sql语句的结构发生了变化,最终可以在没有用户名或者密码的情况下进行登录。
参数占位符
在Mybatis中提供的参数占位符有两种:${...} 、#{...}
- #{...}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
- 性能比后者高
- ${...}
- 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名、列表进行动态设置时使用
注意事项:在项目开发中,建议使用#{...},生成预编译SQL,防止SQL注入安全。
新增
SQL语句:
1 | insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values ('songyuanqiao','宋远桥',1,'1.jpg',2,'2012-10-09',2,'2022-10-01 10:00:00','2022-10-01 10:00:00'); |
接口方法:
1 |
|
说明:#{...} 里面写的名称是对象的属性名
测试类:
1 | import com.nicccce.mapper.EmpMapper; |
主键返回
在数据添加成功后,需要获取插入数据库数据的主键,以供进一步使用(如,设置外键)。
那要如何实现在插入数据之后返回所插入行的主键值呢?
默认情况下,执行插入操作时,是不会主键值返回的。
如果我们想要拿到主键值,需要在Mapper接口中的方法上添加一个Options注解,
并在注解中指定属性
useGeneratedKeys=true和keyProperty="实体类属性名"
主键返回代码实现:
1 |
|
测试:
1 |
|
更新
SQL语句:
1 | update emp set username = 'linghushaoxia', name = '令狐少侠', gender = 1 , image = '1.jpg' , job = 2, entrydate = '2012-01-01', dept_id = 2, update_time = '2022-10-01 12:12:12' where id = 18; |
接口方法:
1 |
|
测试类:
1 |
|
查询
根据ID查询
SQL语句:
1 | select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp where id=1; |
接口方法:
1 |
|
测试类:
1 |
|
而在测试的过程中,发现有几个字段(deptId、createTime、updateTime)是没有封装进去的,但是在数据表中是有值的。
数据封装
- 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
解决方案:
- 起别名
- 结果映射
- 开启驼峰命名
起别名:在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样
1 |
|
手动结果映射:通过 @Results及@Result 进行手动结果映射,column=“表中的字段名”,property=“类中的属性名”
1 |
|
@Results源代码:
2
3
4
5
6
7
8
public Results {
String id() default "";
Result[] value() default {}; //Result类型的数组
}@Result源代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public Result {
boolean id() default false;//表示当前列是否为主键(true:是主键)
String column() default "";//指定表中字段名
String property() default "";//指定类中属性名
Class<?> javaType() default void.class;
JdbcType jdbcType() default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UnknownTypeHandler.class;
One one() default ;
Many many() default ;
}
开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
1 | # 在application.properties中添加: |
要使用驼峰命名前提是 实体类的属性 与 数据库表中的字段名严格遵守驼峰命名。
条件查询
SQL语句:
1 | select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time |
接口方法:
方式一
因为#{...}会在预编译中被 ? 替代,而 ? 是不允许直接出现在字符串中的,因此“%#{...}%”是非法的
1 |
|
注意:
方法中的形参名和SQL语句中的参数占位符名保持一致
模糊查询使用${...}进行字符串拼接,这种方式呢,由于是字符串拼接,并不是预编译的形式,所以效率不高、且存在sql注入风险。
- 方式二(解决SQL注入风险)
- 使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%')
1 |
|
执行结果:生成的SQL都是预编译的SQL语句(性能高、安全)
参数名说明
在上面我们所编写的条件查询功能中,我们需要保证接口中方法的形参名和SQL语句中的参数占位符名相同
参数名在不同的SpringBoot版本中,处理方案还不同:
- 在springBoot的2.x版本(保证参数名一致)
springBoot的父工程对compiler编译插件进行了默认的参数parameters配置,使得在编译时,会在生成的字节码文件中保留原方法形参的名称,所以#{…}里面可以直接通过形参名获取对应的值
在springBoot的1.x版本/单独使用mybatis(使用@Param注解来指定SQL语句中的参数名)
1
2
3
4
5
6
7
8
9
10
11
public interface EmpMapper {
public List<Emp> list(String name, Short gender, begin)LocalDate begin, LocalDate end);
}
在编译时,生成的字节码文件当中,不会保留Mapper接口中方法的形参名称,而是使用var1、var2、...这样的形参名字,此时要获取参数值时,就要通过@Param注解来指定SQL语句中的参数名
XML配置文件
Mybatis的开发有两种方式:
- 注解
- XML
规范
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名:
com.包名.mapper.Mapper名)由于maven的java目录下只能放java文件,因此XML文件放在resources目录下,最终为
resources.com.包名.mapper.Mapper名XML映射文件的namespace属性为Mapper接口全限定名一致
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
<select>标签:就是用于编写select查询语句的。
- resultType属性,指的是查询返回的单条记录所封装的类型。
实现
第1步:创建XML映射文件
resources目录下,创建包名使用
/分隔,即com/包名/mapper
第2步:编写XML映射文件
xml映射文件中的dtd约束,直接从mybatis官网复制即可
1 |
|
配置:XML映射文件的namespace属性为Mapper接口全限定名
1 |
|
配置:XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致
1 |
|
<select>标签:就是用于编写select查询语句的。
- resultType属性,指的是查询返回的单条记录所封装的类型。
实现mapper
1 |
|
MybatisX
MybatisX是一款基于IDEA的快速开发Mybatis的插件,为效率而生。
可以通过MybatisX快速定位XML文件和mapper的位置。
- 到底是使用注解方式开发还是使用XML方式开发?
官方说明:https://mybatis.net.cn/getting-started.html
结论:使用Mybatis的注解,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句。
Mybatis动态SQL
在页面原型中,列表上方的条件是动态的,是可以不传递的,也可以只传递其中的1个或者2个或者全部。
而在我们刚才编写的SQL语句中,我们会看到,我们将三个条件直接写死了。 如果页面只传递了参数姓名name 字段,其他两个字段 性别 和 入职时间没有传递,那么这两个参数的值就是null。
此时,执行的SQL语句的查询结果是不正确的。正确的做法应该是:传递了参数,再组装这个查询条件;如果没有传递参数,就不应该组装这个查询条件。
比如:如果姓名输入了"张", 对应的SQL为:
1 | select * from emp where name like '%张%' order by update_time desc; |
如果姓名输入了"张",,性别选择了"男",则对应的SQL为:
1 | select * from emp where name like '%张%' and gender = 1 order by update_time desc; |
SQL语句会随着用户的输入或外部条件的变化而变化,我们称为:动态SQL。
在Mybatis中提供了很多实现动态SQL的标签,我们学习Mybatis中的动态SQL就是掌握这些动态SQL标签。
if
<if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
1 | <if test="条件表达式"> |
接下来,我们就通过<if>标签来改造之前条件查询的案例。
条件查询
示例:把SQL语句改造为动态SQL方式
- 原有的SQL语句
1 | <select id="list" resultType="com.nicccce.pojo.Emp"> |
- 动态SQL语句
1 | <select id="list" resultType="com.nicccce.pojo.Emp"> |
测试方法:
1 |
|
修改测试方法中的代码,再次进行测试,观察执行情况:
1 |
|
执行的SQL语句变成了select * from emp where and gender = ? order by update_time desc,发现多了一个and,报错了
再次修改测试方法中的代码,再次进行测试:
1 |
|
执行的SQL语句变成了select * from emp where order by update_time desc,多了个where,也报错了
以上问题的解决方案:使用<where>标签代替SQL语句中的where关键字
<where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR
1 | <select id="list" resultType="com.nicccce.pojo.Emp"> |
测试方法:
1 |
|
更新信息
1 |
|
修改测试方法:
1 |
|
执行的SQL语句:updete emp set username=?, where id=?,多了一个逗号
解决方案:使用<set>标签代替SQL语句中的set关键字
<set>:动态的在SQL语句中插入set关键字,并会删掉额外的逗号。(用于update语句中)
1 |
|
小结
<if>用于判断条件是否成立,如果条件为true,则拼接SQL
形式:
1
<if test="name != null"> … </if>
<where>- where元素只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR
<set>- 动态地在行首插入 SET 关键字,并会删掉额外的逗号。(用在update语句中)
foreach
案例:员工删除功能(既支持删除单条记录,又支持批量删除)
SQL语句:
1 | delete from emp where id in (1,2,3); |
Mapper接口:
1 |
|
XML映射文件:
- 使用
<foreach>遍历deleteByIds方法中传递的参数ids集合
1 | <foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符" |
1 |
|
执行的SQL语句:delete from emp where id in (?,?,?)
sql&include
问题分析:
- 在xml映射文件中配置的SQL,有时可能会存在很多重复的片段,此时就会存在很多冗余的代码,如`select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp
我们可以对重复的代码片段进行抽取,将其通过<sql>标签封装到一个SQL片段,然后再通过<include>标签进行引用。
<sql>:定义可重用的SQL片段<include>:通过属性refid,指定包含的SQL片段
SQL片段: 抽取重复的代码
1 | <sql id="commonSelect"> |
然后通过<include>
标签在原来抽取的地方进行引用。操作如下:
1 | <select id="list" resultType="com.nicccce.pojo.Emp"> |
REST开发规范
在前后端分离的开发模式中,前后端开发人员都需要根据提前定义好的接口文档,来进行前后端功能的开发。
而在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
- REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
传统URL风格如下:
1 | http://localhost:8080/user/getById?id=1 GET:查询id为1的用户 |
我们看到,原始的传统URL呢,定义比较复杂,而且将资源的访问行为对外暴露出来了。
基于REST风格URL如下:
1 | http://localhost:8080/users/1 GET:查询id为1的用户 |
其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
在REST风格的URL中,通过四种请求方式,来操作数据的增删改查。
- GET : 查询
- POST :新增
- PUT :修改
- DELETE :删除
我们看到如果是基于REST风格,定义URL,URL将会更加简洁、更加规范、更加优雅。
注意事项:
- REST是风格,是约定方式,约定不是规定,可以打破
- 描述模块的功能通常使用复数,也就是加s的格式来描述,表示此类资源,而非单个资源。如:users、emps、books…
PageHelper插件
PageHelper是Mybatis的一款功能强大、方便易用的分页插件,支持任何形式的单标、多表的分页查询。
官网:https://pagehelper.github.io/
在执行empMapper.list()方法时,就是执行:select * from emp 语句,怎么能够实现分页操作呢?
分页插件帮我们完成了以下操作:
- 先获取到要执行的SQL语句:select * from emp
- 把SQL语句中的字段列表,变为:count(*)
- 执行SQL语句:select count(*) from emp //获取到总记录数
- 再对要执行的SQL语句:select * from emp 进行改造,在末尾添加 limit ? , ?
- 执行改造后的SQL语句:select * from emp limit ? , ?
代码实现
当使用了PageHelper分页插件进行分页,就无需再Mapper中进行手动分页了。 在Mapper中我们只需要进行正常的列表查询即可。在Service层中,调用Mapper的方法之前设置分页参数,在调用Mapper方法执行查询之后,解析分页结果,并将结果封装到PageBean对象中返回。
1 |
|
1、在pom.xml引入依赖
1 | <dependency> |
2、EmpMapper
1 |
|
3、EmpServiceImpl
1 |
|
有条件的分页查询
EmpController
1 |
|
EmpService
1 | public interface EmpService { |
EmpServiceImpl
1 |
|
EmpMapper
1 |
|
EmpMapper.xml
1 |
|
文件上传
文件上传,是指将本地图片、视频、音频等文件上传到服务器,供其他用户浏览或下载的过程。
文件上传在项目中应用非常广泛,我们经常发微博、发微信朋友圈都用到了文件上传功能。
前端
在前端程序中要完成哪些代码:
1 | <form action="/upload" method="post" enctype="multipart/form-data"> |
上传文件的原始form表单,要求表单必须具备以下三点(上传文件页面三要素):
表单必须有file域,用于选择要上传的文件
1
<input type="file" name="image"/>
表单提交方式必须为POST
通常上传的文件会比较大,所以需要使用 POST 提交方式
表单的编码类型enctype必须要设置为:multipart/form-data
普通默认的编码格式是不适合传输大型的二进制数据的,所以在文件上传时,表单的编码格式必须设置为multipart/form-data
删除form表单中enctype属性值,会是什么情况?
此时表单的编码格式为默认值,提交后仅仅提交了该文件的名字
后端
首先在服务端定义这么一个controller,用来进行文件上传,然后在controller当中定义一个方法来处理
/upload请求在定义的方法中接收提交过来的数据 (方法中的形参名和请求参数的名字保持一致)
- 用户名:String name
- 年龄: Integer age
- 文件: MultipartFile image
Spring中提供了一个API:MultipartFile,使用这个API就可以来接收到上传的文件
问题:如果表单项的名字和方法中形参名不一致,该怎么办?
- ~~~javascript public Result upload(String username, Integer age, MultipartFile file) //file形参名和请求参数名image不一致
2
3
4
5
6
7
解决:使用@RequestParam注解进行参数绑定
- ~~~java
public Result upload(String username,
Integer age,
@RequestParam("image") MultipartFile file)
UploadController代码:
1 |
|
本地存储
前面我们已分析了文件上传功能前端和后端的基础代码实现,文件上传时在服务端会产生一个临时文件,请求响应完成之后,这个临时文件被自动删除,并没有进行保存。下面呢,我们就需要完成将上传的文件保存在服务器的本地磁盘上。
代码实现:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
1 |
|
但是由于我们是使用原始文件名作为所上传文件的存储名字,当我们再次上传一个名为1.jpg文件时,发现会把之前已经上传成功的文件覆盖掉。
解决方案:保证每次上传文件时文件名都唯一的(使用UUID(通用唯一识别码)获取随机文件名)
1 |
|
在解决了文件名唯一性的问题后,我们再次上传一个较大的文件(超出1M)时发现,后端程序报错。
报错原因呢是因为:在SpringBoot中,文件上传时默认单个文件最大大小为1M
那么如果需要上传大文件,可以在application.properties进行如下配置:
1 | #配置单个文件最大上传大小 |
如果直接存储在服务器的磁盘目录中,存在以下缺点:
- 不安全:磁盘如果损坏,所有的文件就会丢失
- 容量有限:如果存储大量的图片,磁盘空间有限(磁盘不可能无限制扩容)
- 无法直接访问
为了解决上述问题呢,通常有两种解决方案:
- 自己搭建存储服务器,如:fastDFS 、MinIO
- 使用现成的云服务,如:阿里云,腾讯云,华为云
阿里云OSS
准备
阿里云是阿里巴巴集团旗下全球领先的云计算公司,也是国内最大的云服务提供商 。
阿里云对象存储OSS(Object Storage Service),是一款海量、安全、低成本、高可靠的云存储服务。使用OSS,您可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种文件。
在我们使用了阿里云OSS对象存储服务之后,我们的项目当中如果涉及到文件上传这样的业务,在前端进行文件上传并请求到服务端时,在服务器本地磁盘当中就不需要再来存储文件了。我们直接将接收到的文件上传到oss,由 oss帮我们存储和管理,同时阿里云的oss存储服务还保障了我们所存储内容的安全可靠。
SDK:Software Development Kit 的缩写,软件开发工具包,包括辅助软件开发的依赖(jar包)、代码示例等,都可以叫做SDK。
简单说,sdk中包含了我们使用第三方云服务时所需要的依赖,以及一些示例代码。我们可以参照sdk所提供的示例代码就可以完成入门程序。
第三方服务使用的通用思路,我们做一个简单介绍之后,接下来我们就来介绍一下我们当前要使用的阿里云oss对象存储服务具体的使用步骤。
Bucket:存储空间是用户用于存储对象(Object,就是文件)的容器,所有的对象都必须隶属于某个存储空间。
下面我们根据之前介绍的使用步骤,完成准备工作:
注册阿里云账户(注册完成后需要实名认证)
注册完账号之后,就可以登录阿里云
通过控制台找到对象存储OSS服务
如果是第一次访问,还需要开通对象存储服务OSS
开通OSS服务之后,就可以进入到阿里云对象存储的控制台
点击左侧的 "Bucket列表",创建一个Bucket
大家可以参照"资料\04. 阿里云oss"中提供的文档,开通阿里云OSS服务。
入门
阿里云oss 对象存储服务的准备工作我们已经完成了,接下来我们就来完成第二步操作:参照官方所提供的sdk示例来编写入门程序。
首先我们需要来打开阿里云OSS的官方文档,在官方文档中找到 SDK 的示例代码:
参照官方提供的SDK,改造一下,即可实现文件上传功能:
1 | import com.aliyun.oss.ClientException; |
在以上代码中,需要替换的内容为:
- accessKeyId:阿里云账号AccessKey
- accessKeySecret:阿里云账号AccessKey对应的秘钥
- bucketName:Bucket名称
- objectName:对象名称,在Bucket中存储的对象的名称
- filePath:文件路径
运行以上程序后,会把本地的文件上传到阿里云OSS服务器上:
集成
阿里云oss对象存储服务的准备工作以及入门程序我们都已经完成了,接下来我们就需要在案例当中集成oss对象存储服务,来存储和管理案例中上传的图片。
在新增员工的时候,上传员工的图像,而之所以需要上传员工的图像,是因为将来我们需要在系统页面当中访问并展示员工的图像。而要想完成这个操作,需要做两件事:
- 需要上传员工的图像,并把图像保存起来(存储到阿里云OSS)
- 访问员工图像(通过图像在阿里云OSS的存储地址访问图像)
- OSS中的每一个文件都会分配一个访问的url,通过这个url就可以访问到存储在阿里云上的图片。所以需要把url返回给前端,这样前端就可以通过url获取到图像。
我们参照接口文档来开发文件上传功能:
基本信息
1
2
3
4
5请求路径:/upload
请求方式:POST
接口描述:上传图片接口请求参数
参数格式:multipart/form-data
参数说明:
参数名称 参数类型 是否必须 示例 备注 image file 是 响应数据
参数格式:application/json
参数说明:
参数名 类型 是否必须 备注 code number 必须 响应码,1 代表成功,0 代表失败 msg string 非必须 提示信息 data object 非必须 返回的数据,上传图片的访问路径 响应数据样例:
1
2
3
4
5{
"code": 1,
"msg": "success",
"data": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-0400.jpg"
}
引入阿里云OSS上传文件工具类(由官方的示例代码改造而来)
1 | import com.aliyun.oss.OSS; |
修改UploadController代码:
1 | import com.nicccce.pojo.Result; |
配置文件
员工管理的增删改查功能我们已开发完成,但在我们所开发的程序中还一些小问题,下面我们就来分析一下当前案例中存在的问题以及如何优化解决。
参数配置化
在我们之前编写的程序中进行文件上传时,需要调用AliOSSUtils工具类,将文件上传到阿里云OSS对象存储服务当中。而在调用工具类进行文件上传时,需要一些参数:
- endpoint //阿里云OSS域名
- accessKeyID //用户身份ID
- accessKeySecret //用户密钥
- bucketName //存储空间的名字
关于以上的这些阿里云相关配置信息,我们是直接写死在java代码中了(硬编码),如果我们在做项目时每涉及到一个第三方技术服务,就将其参数硬编码,那么在Java程序中会存在两个问题:
- 如果这些参数发生变化了,就必须在源程序代码中改动这些参数,然后需要重新进行代码的编译,将Java代码编译成class字节码文件再重新运行程序。(比较繁琐)
- 如果我们开发的是一个真实的企业级项目, Java类可能会有很多,如果将这些参数分散的定义在各个Java类当中,我们要修改一个参数值,我们就需要在众多的Java代码当中来定位到对应的位置,再来修改参数,修改完毕之后再重新编译再运行。(参数配置过于分散,是不方便集中的管理和维护)
为了解决以上分析的问题,我们可以将参数配置在配置文件中。如下:
1 | #自定义的阿里云OSS配置信息 |
在将阿里云OSS配置参数交给properties配置文件来管理之后,我们的AliOSSUtils工具类就变为以下形式:
1 |
|
而此时如果直接调用AliOSSUtils类当中的upload方法进行文件上传时,这4项参数全部为null,原因是因为并没有给它赋值。
此时我们是不是需要将配置文件当中所配置的属性值读取出来,并分别赋值给AliOSSUtils工具类当中的各个属性呢?那应该怎么做呢?
因为application.properties是springboot项目默认的配置文件,所以springboot程序在启动时会默认读取application.properties配置文件,而我们可以使用一个现成的注解:@Value,获取配置文件中的数据。
@Value 注解通常用于外部配置的属性注入,具体用法为: @Value("${配置文件中的key}")
1 |
|
yml配置文件
前面我们一直使用springboot项目创建完毕后自带的application.properties进行属性的配置,那其实呢,在springboot项目当中是支持多种配置方式的,除了支持properties配置文件以外,还支持另外一种类型的配置文件,就是我们接下来要讲解的yml格式的配置文件。
application.properties
1
2server.port=8080
server.address=127.0.0.1application.yml
1
2
3server:
port: 8080
address: 127.0.0.1application.yaml
1
2
3server:
port: 8080
address: 127.0.0.1
yml 格式的配置文件,后缀名有两种:
- yml (推荐)
- yaml
我们可以看到配置同样的数据信息,yml格式的数据有以下特点:
- 容易阅读
- 容易与脚本语言交互
- 以数据为核心,重数据轻格式
下yml配置文件的基本语法:
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
yml文件中常见的数据格式:
- 定义对象或Map集合
- 定义数组、list或set集合
对象/Map集合
1 | user: |
数组/List/Set集合
1 | hobby: |
熟悉完了yml文件的基本语法后,我们修改下之前案例中使用的配置文件,变更为application.yml配置方式:
- 修改application.properties名字为:
_application.properties(名字随便更换,只要加载不到即可) - 创建新的配置文件:
application.yml
原有application.properties文件:
1 | spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver |

新建的application.yml文件:
1 | spring: |
@ConfigurationProperties
我们在application.properties或者application.yml中配置了阿里云OSS的四项参数之后,如果java程序中需要这四项参数数据,我们直接通过@Value注解来进行注入。这种方式本身没有什么问题问题,但是如果说需要注入的属性较多(例:需要20多个参数数据),我们写起来就会比较繁琐。
在Spring中给我们提供了一种简化方式,可以直接将配置文件中配置项的值自动的注入到对象的属性中。
Spring提供的简化方式套路:
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象
在实体类上添加
@ConfigurationProperties注解,并通过perfect属性来指定配置参数项的前缀
实体类:AliOSSProperties
1 | import lombok.Data; |
AliOSSUtils工具类:
1 | import com.aliyun.oss.OSS; |
这个警告提示是告知我们还需要引入一个依赖:
1 | <dependency> |
当我们在pom.xml文件当中配置了这项依赖之后,我们重新启动服务,大家就会看到在properties或者是yml配置文件当中,就会提示阿里云
OSS
相关的配置项。所以这项依赖它的作用就是会自动的识别被@Configuration Properties注解标识的bean对象。
@ConfigurationProperties注解我们已经介绍完了,接下来我们就来区分一下@ConfigurationProperties注解以及我们前面所介绍的另外一个@Value注解:
相同点:都是用来注入外部配置的属性的。
不同点:
@Value注解只能一个一个的进行外部属性的注入。
@ConfigurationProperties可以批量的将外部的属性配置注入到bean对象的属性中。
如果要注入的属性非常的多,并且还想做到复用,就可以定义这么一个bean对象。通过 configuration properties 批量的将外部的属性配置直接注入到 bin 对象的属性当中。在其他的类当中,我要想获取到注入进来的属性,我直接注入 bin 对象,然后调用 get 方法,就可以获取到对应的属性值了
登录认证
登录功能
LoginController
1 |
|
EmpService
1 | public interface EmpService { |
EmpServiceImpl
1 |
|
EmpMapper
1 |
|
登录校验
以上的功能无论用户是否登录,都可以访问部门管理以及员工管理的相关数据。所以我们目前所开发的登录功能,它只是徒有其表。而我们要想解决这个问题,我们就需要完成一步非常重要的操作:登录校验。
登录校验:
- 所谓登录校验,指的是我们在服务器端接收到浏览器发送过来的请求之后,首先我们要对请求进行校验。先要校验一下用户登录了没有,如果用户已经登录了,就直接执行对应的业务操作就可以了;如果用户没有登录,此时就不允许他执行相关的业务操作,直接给前端响应一个错误的结果,最终跳转到登录页面,要求他登录成功之后,再来访问对应的数据。
首先我们在宏观上先有一个认知:
前面在讲解HTTP协议的时候,我们提到HTTP协议是无状态协议。什么又是无状态的协议?
所谓无状态,指的是每一次请求都是独立的,下一次请求并不会携带上一次请求的数据。而浏览器与服务器之间进行交互,基于HTTP协议也就意味着现在我们通过浏览器来访问了登陆这个接口,实现了登陆的操作,接下来我们在执行其他业务操作时,服务器也并不知道这个员工到底登陆了没有。因为HTTP协议是无状态的,两次请求之间是独立的,所以是无法判断这个员工到底登陆了没有。
那应该怎么来实现登录校验的操作呢?具体的实现思路可以分为两部分:
- 在员工登录成功后,需要将用户登录成功的信息存起来,记录用户已经登录成功的标记。
- 在浏览器发起请求时,需要在服务端进行统一拦截,拦截后进行登录校验。
我们要完成以上操作,会涉及到web开发中的两个技术:
- 会话技术
- 统一拦截技术
而统一拦截技术现实方案也有两种:
- Servlet规范中的Filter过滤器
- Spring提供的interceptor拦截器
会话技术
在web开发当中,会话指的就是浏览器与服务器之间的一次连接,我们就称为一次会话。
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
比如:打开了浏览器来访问web服务器上的资源(浏览器不能关闭、服务器不能断开)
- 第1次:访问的是登录的接口,完成登录操作
- 第2次:访问的是部门管理接口,查询所有部门数据
- 第3次:访问的是员工管理接口,查询员工数据
只要浏览器和服务器都没有关闭,以上3次请求都属于一次会话当中完成的。
需要注意的是:会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。
知道了会话的概念了,接下来我们再来了解下会话跟踪。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据。
服务器会接收很多的请求,但是服务器是需要识别出这些请求是不是同一个浏览器发出来的。比如:1和2这两个请求是不是同一个浏览器发出来的,3和5这两个请求不是同一个浏览器发出来的。如果是同一个浏览器发出来的,就说明是同一个会话。如果是不同的浏览器发出来的,就说明是不同的会话。而识别多次请求是否来自于同一浏览器的过程,我们就称为会话跟踪。
我们使用会话跟踪技术就是要完成在同一个会话中,多个请求之间进行共享数据。
为什么要共享数据呢?
由于HTTP是无状态协议,在后面请求中怎么拿到前一次请求生成的数据呢?此时就需要在一次会话的多次请求之间进行数据共享
会话跟踪技术有两种:
- Cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- Session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
会话跟踪方案
- Cookie
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的,我们使用 cookie 来跟踪会话,我们就可以在浏览器第一次发起请求来请求服务器的时候,我们在服务器端来设置一个cookie。
比如第一次请求了登录接口,登录接口执行完成之后,我们就可以设置一个cookie,在 cookie 当中我们就可以来存储用户相关的一些数据信息。比如我可以在 cookie 当中来存储当前登录用户的用户名,用户的ID。
服务器端在给客户端在响应数据的时候,会自动的将 cookie 响应给浏览器,浏览器接收到响应回来的 cookie 之后,会自动的将 cookie 的值存储在浏览器本地。接下来在后续的每一次请求当中,都会将浏览器本地所存储的 cookie 自动地携带到服务端。
接下来在服务端我们就可以获取到 cookie 的值。我们可以去判断一下这个 cookie 的值是否存在,如果不存在这个cookie,就说明客户端之前是没有访问登录接口的;如果存在 cookie 的值,就说明客户端之前已经登录完成了。这样我们就可以基于 cookie 在同一次会话的不同请求之间来共享数据。
我刚才在介绍流程的时候,用了 3 个自动:
服务器会 自动 的将 cookie 响应给浏览器。
浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
为什么这一切都是自动化进行的?
是因为 cookie 它是 HTP 协议当中所支持的技术,而各大浏览器厂商都支持了这一标准。在 HTTP 协议官方给我们提供了一个响应头和请求头:
响应头 Set-Cookie :设置Cookie数据的
请求头 Cookie:携带Cookie数据的
代码测试
1 | //简化日志记录 |
A. 访问c1接口,设置Cookie,http://localhost:8080/c1
我们可以看到,设置的cookie,通过响应头Set-Cookie响应给浏览器,并且浏览器会将Cookie,存储在浏览器端。
B. 访问c2接口 http://localhost:8080/c2,此时浏览器会自动的将Cookie携带到服务端,是通过请求头Cookie,携带的。
优缺点
- 优点:HTTP协议中支持的技术(像Set-Cookie 响应头的解析以及 Cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的)
- 缺点:
- 移动端APP(Android、IOS)中无法使用Cookie
- 不安全,用户可以自己禁用Cookie
- Cookie不能跨域
跨域:
- 现在的项目,大部分都是前后端分离的,前后端最终也会分开部署,前端部署在服务器 192.168.150.200 上,端口 80,后端部署在 192.168.150.100上,端口 8080
- 我们打开浏览器直接访问前端工程,访问url:http://192.168.150.200/login.html
- 然后在该页面发起请求到服务端,而服务端所在地址不再是localhost,而是服务器的IP地址192.168.150.100,假设访问接口地址为:http://192.168.150.100:8080/login
- 那此时就存在跨域操作了,因为我们是在 http://192.168.150.200/login.html 这个页面上访问了http://192.168.150.100:8080/login 接口
- 此时如果服务器设置了一个Cookie,这个Cookie是不能使用的,因为Cookie无法跨域
区分跨域的维度:
- 协议
- IP/协议
- 端口
只要上述的三个维度有任何一个维度不同,那就是跨域操作
举例:
http://192.168.150.200/login.html ----------> https://192.168.150.200/login [协议不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.100/login [IP不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login [端口不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200/login [不跨域]
- Session
Session 的底层其实就是基于我们刚才所介绍的 Cookie 来实现的。
获取Session
如果我们现在要基于 Session 来进行会话跟踪,浏览器在第一次请求服务器的时候,我们就可以直接在服务器当中来获取到会话对象Session。如果是第一次请求Session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象Session 。而每一个会话对象Session ,它都有一个ID,我们称之为 Session 的ID。
响应Cookie (JSESSIONID)
接下来,服务器端在给浏览器响应数据的时候,它会将 Session 的 ID 通过 Cookie 响应给浏览器。其实在响应头当中增加了一个 Set-Cookie 响应头。这个 Set-Cookie 响应头对应的值是不是cookie? cookie 的名字是固定的,JSESSIONID 代表的服务器端会话对象 Session 的 ID。浏览器会自动识别这个响应头,然后自动将Cookie存储在浏览器本地。
查找Session
接下来,在后续的每一次请求当中,都会将 Cookie 的数据获取出来,并且携带到服务端。接下来服务器拿到JSESSIONID这个 Cookie 的值,也就是 Session 的ID。拿到 ID 之后,就会从众多的 Session 当中来找到当前请求对应的会话对象Session。
代码测试
1 |
|
A. 访问 s1 接口,http://localhost:8080/s1
请求完成之后,在响应头中,就会看到有一个Set-Cookie的响应头,里面响应回来了一个Cookie,就是JSESSIONID,这个就是服务端会话对象 Session 的ID。
B. 访问 s2 接口,http://localhost:8080/s2
接下来,在后续的每次请求时,都会将Cookie的值,携带到服务端,那服务端接收到Cookie之后,会自动的根据JSESSIONID的值,找到对应的会话对象Session。
那经过这两步测试,大家也会看到,在控制台中输出如下日志:
1 | 12:04:05.331 INFO 13456 --- [io-8080-exec-10] c.nicccce.controller.SessionController : HttpSession-s1: 1675666466 |
两次请求,获取到的Session会话对象的hashcode是一样的,就说明是同一个会话对象。而且,第一次请求时,往Session会话对象中存储的值,第二次请求时,也获取到了。 那这样,我们就可以通过Session会话对象,在同一个会话的多次请求之间来进行数据共享了。
优缺点
- 优点:Session是存储在服务端的,安全(只是通过Cookies中的id来确定响应会话的对象)
- 缺点:
- 服务器集群环境下无法直接使用Session
- 移动端APP(Android、IOS)中无法使用Cookie
- 用户可以自己禁用Cookie
- Cookie不能跨域
服务器集群环境为何无法使用Session?
首先第一点,我们现在所开发的项目,一般都不会只部署在一台服务器上,因为一台服务器会存在一个很大的问题,就是单点故障。所谓单点故障,指的就是一旦这台服务器挂了,整个应用都没法访问了。
所以在现在的企业项目开发当中,最终部署的时候都是以集群的形式来进行部署,也就是同一个项目它会部署多份。比如这个项目我们现在就部署了 3 份。
而用户在访问的时候,到底访问这三台其中的哪一台?其实用户在访问的时候,他会访问一台前置的服务器,我们叫负载均衡服务器,它的作用就是将前端发起的请求均匀的分发给后面的这三台服务器。
此时假如我们通过 session 来进行会话跟踪,可能就会存在这样一个问题。用户打开浏览器要进行登录操作,此时会发起登录请求。登录请求到达负载均衡服务器,将这个请求转给了第一台 Tomcat 服务器。
Tomcat 服务器接收到请求之后,要获取到会话对象session。获取到会话对象 session 之后,要给浏览器响应数据,最终在给浏览器响应数据的时候,就会携带这么一个 cookie 的名字,就是 JSESSIONID ,下一次再请求的时候,是不是又会将 Cookie 携带到服务端?
好。此时假如又执行了一次查询操作,要查询部门的数据。这次请求到达负载均衡服务器之后,负载均衡服务器将这次请求转给了第二台 Tomcat 服务器,此时他就要到第二台 Tomcat 服务器当中。根据JSESSIONID 也就是对应的 session 的 ID 值,要找对应的 session 会话对象。
我想请问在第二台服务器当中有没有这个ID的会话对象 Session, 是没有的。此时是不是就出现问题了?我同一个浏览器发起了 2 次请求,结果获取到的不是同一个会话对象,这就是Session这种会话跟踪方案它的缺点,在服务器集群环境下无法直接使用Session。
令牌技术(Token)
这里我们所提到的令牌,其实它就是一个用户身份的标识,看似很高大上,很神秘,其实本质就是一个字符串。
如果通过令牌技术来跟踪会话,我们就可以在浏览器发起请求。在请求登录接口的时候,如果登录成功,我就可以生成一个令牌,令牌就是用户的合法身份凭证。接下来我在响应数据的时候,我就可以直接将令牌响应给前端。
接下来我们在前端程序当中接收到令牌之后,就需要将这个令牌存储起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localStorage)当中。
接下来,在后续的每一次请求当中,都需要将令牌携带到服务端。携带到服务端之后,接下来我们就需要来校验令牌的有效性。如果令牌是有效的,就说明用户已经执行了登录操作,如果令牌是无效的,就说明用户之前并未执行登录操作。
此时,如果是在同一次会话的多次请求之间,我们想共享数据,我们就可以将共享的数据存储在令牌当中就可以了。
优缺点
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
针对于这三种方案,现在企业开发当中使用的最多的就是第三种令牌技术进行会话跟踪。而前面的这两种传统的方案,现在企业项目开发当中已经很少使用了。所以在我们的课程当中,我们也将会采用令牌技术来解决案例项目当中的会话跟踪问题。
JWT令牌
JWT全称:JSON Web Token (官网:https://jwt.io/)
定义了一种简洁的、自包含的格式,用于在通信双方以json数据格式安全的传输信息。由于数字签名的存在,这些信息是可靠的。
简洁:是指jwt就是一个简单的字符串。可以在请求参数或者是请求头当中直接传递。
自包含:指的是jwt令牌,看似是一个随机的字符串,但是我们是可以根据自身的需求在jwt令牌中存储自定义的数据内容。如:可以直接在jwt令牌中存储用户的相关信息。
简单来讲,jwt就是将原始的json数据格式进行了安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT的组成: (JWT令牌由三个部分组成,三个部分之间使用英文的点来分割)
第一部分:Header(头),有令牌的类型和所使用的签名算法,如HMAC、SHA256、RSA;使用Base64编码组成;(Base64是一种编码,不是一种加密过程,可以被翻译成原来的样子)
1
2
3
4{
"alg" : "HS256",
"type" : "JWT"
}第二部分:有效负载,包含声明;声明是有关实体(通常是用户)和其他数据的声明,不放用户敏感的信息,如密码。同样使用Base64编码
1
2
3
4
5{
"sub" : "123",
"name" : "John Do",
"admin" : true
}第三部分:Signature(签名),前面两部分都使用Base64进行编码,前端可以解开知道里面的信息。Signature需要使用编码后的header和payload 加上我们提供的一个密钥,使用header中指定的签名算法(HS256)进行签名。签名的作用是保证JWT没有被篡改过
1
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret);
签名的目的就是为了防jwt令牌被篡改,而正是因为jwt令牌最后一个部分数字签名的存在,所以整个jwt 令牌是非常安全可靠的。一旦jwt令牌当中任何一个部分、任何一个字符被篡改了,整个令牌在校验的时候都会失败,所以它是非常安全可靠的。
JWT是如何将原始的JSON格式数据,转变为字符串的呢?
其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
Base64是编码方式,而不是加密方式。
JWT令牌最典型的应用场景就是登录认证:
- 在浏览器发起请求来执行登录操作,此时会访问登录的接口,如果登录成功之后,我们需要生成一个jwt令牌,将生成的 jwt令牌返回给前端。
- 前端拿到jwt令牌之后,会将jwt令牌存储起来。在后续的每一次请求中都会将jwt令牌携带到服务端。
- 服务端统一拦截请求之后,先来判断一下这次请求有没有把令牌带过来,如果没有带过来,直接拒绝访问,如果带过来了,还要校验一下令牌是否是有效。如果有效,就直接放行进行请求的处理。
在JWT登录认证整个流程当中涉及到两步操作:
- 在登录成功之后,要生成令牌。
- 每一次请求当中,要接收令牌并对令牌进行校验。
稍后我们再来学习如何来生成jwt令牌,以及如何来校验jwt令牌。
生成和校验
首先我们先来实现JWT令牌的生成。要想使用JWT令牌,需要先引入JWT的依赖:
1 | <!-- JWT依赖--> |
在引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验
工具类:Jwts
生成JWT代码实现:
1 |
|
控制台输出:
1 | eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjcyNzI5NzMwfQ.fHi0Ub8npbyt71UqLXDdLyipptLgxBUg_mSuGJtXtBk |
输出的结果就是生成的JWT令牌,,通过英文的点分割对三个部分进行分割,我们可以将生成的令牌复制一下,然后打开JWT的官网,将生成的令牌直接放在Encoded位置,此时就会自动的将令牌解析出来。
| HEADER:ALGORITHM & TOKEN TYPE |
|
{ "alg": "HS256", "typ": "JWT" } |
| PAYLOAD:DATA |
|
{ "id": 1, "exp": 1672729730 } |
| VERIFY SIGNATURE |
|
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), your-256-bit-secret ) secret base64 encoded |
第一部分解析出来,看到JSON格式的原始数据,所使用的签名算法为HS256。
第二个部分是我们自定义的数据,之前我们自定义的数据就是id,还有一个exp代表的是我们所设置的过期时间。
由于前两个部分是base64编码,所以是可以直接解码出来。但最后一个部分并不是base64编码,是经过签名算法计算出来的,所以最后一个部分是不会解析的。
实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
1 |
|
控制台输出:
1 | {id=1, exp=1672729730} |
令牌解析后,我们可以看到id和过期时间,如果在解析的过程当中没有报错,就说明解析成功了。
把令牌header中的数字9变为8,运行测试方法后发现报错:
原header: eyJhbGciOiJIUzI1NiJ9
修改为: eyJhbGciOiJIUzI1NiJ8
结论:篡改令牌中的任何一个字符,在对令牌进行解析时都会报错,所以JWT令牌是非常安全可靠的。
修改生成令牌的时指定的过期时间,修改为1分钟
1 |
|
等待1分钟之后运行测试方法发现也报错了,说明:JWT令牌过期后,令牌就失效了,解析的为非法令牌。
通过以上测试,我们在使用JWT令牌时需要注意:
JWT校验时使用的签名秘钥,必须和生成JWT令牌时使用的秘钥是配套的。
如果JWT令牌解析校验时报错,则说明 JWT令牌被篡改 或 失效了,令牌非法。
登录下发令牌
JWT令牌的生成和校验的基本操作我们已经学习完了,接下来我们就需要在案例当中通过JWT令牌技术来跟踪会话。具体的思路我们前面已经分析过了,主要就是两步操作:
生成令牌
- 在登录成功之后来生成一个JWT令牌,并且把这个令牌直接返回给前端
校验令牌
- 拦截前端请求,从请求中获取到令牌,对令牌进行解析校验
生成令牌
JWT令牌怎么返回给前端呢?
接口文档当中关于登录接口的描述(主要看响应数据):
响应数据
参数格式:application/json
参数说明:
名称 类型 是否必须 默认值 备注 其他信息 code number 必须 响应码, 1 成功 ; 0 失败 msg string 非必须 提示信息 data string 必须 返回的数据 , jwt令牌 响应数据样例:
1
2
3
4
5{
"code": 1,
"msg": "success",
"data": "eyJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoi6YeR5bq4IiwiaWQiOjEsInVzZXJuYW1lIjoiamlueW9uZyIsImV4cCI6MTY2MjIwNzA0OH0.KkUc_CXJZJ8Dd063eImx4H9Ojfrr6XMJ-yVzaWCVZCo"
}备注说明(给前端看的)
用户登录成功后,系统会自动下发JWT令牌,然后在后续的每次请求中,都需要在请求头header中携带到服务端,请求头的名称为 token ,值为 登录时下发的JWT令牌。
如果检测到用户未登录,则会返回如下固定错误信息:
1
2
3
4
5{
"code": 0,
"msg": "NOT_LOGIN",
"data": null
}
解读完接口文档中的描述了,目前我们先来完成令牌的生成和令牌的下发,我们只需要生成一个令牌返回给前端就可以了。
实现步骤:
- 引入JWT工具类
- 在项目工程下创建com.nicccce.utils包,并把提供JWT工具类复制到该包下
- 登录完成后,调用工具类生成JWT令牌并返回
JWT工具类(直接cv)
1 | public class JwtUtils { |
登录成功,生成JWT令牌并返回
1 |
|
登录请求完成后,可以看到JWT令牌已经响应给了前端,此时前端就会将JWT令牌存储在浏览器本地。
在当前案例中,JWT令牌存储在浏览器的本地存储空间local storage中了。 local storage是浏览器的本地存储,在移动端也是支持的。
我们在发起一个查询部门数据的请求,此时我们可以看到在请求头中包含一个token(JWT令牌),后续的每一次请求当中,都会将这个令牌携带到服务端。
刚才通过浏览器的开发者工具,我们可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。 有两种主流解决方案来统一拦截到所有的请求校验令牌的有效性:
- Filter过滤器
- Interceptor拦截器
过滤器(Filter)
- Filter表示过滤器,是 JavaWeb三大组件(Servlet、Filter、Listener)之一,其他两者已经很少使用了。
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等,可以避免代码的重复。
基本操作
- 第1步,定义过滤器 :1.定义一个类,实现 Filter 接口,并重写其所有方法。
- 第2步,配置过滤器:Filter类上加 @WebFilter 注解,配置拦截资源的路径。引导类上加 @ServletComponentScan 开启Servlet组件支持。
定义过滤器
1 | //定义一个类,实现一个标准的Filter过滤器的接口 |
init方法:过滤器的初始化方法。在web服务器启动的时候会自动的创建Filter过滤器对象,在创建过滤器对象的时候会自动调用init初始化方法,这个方法只会被调用一次。
doFilter方法:这个方法是在每一次拦截到请求之后都会被调用,所以这个方法是会被调用多次的,每拦截到一次请求就会调用一次doFilter()方法。
destroy方法: 是销毁的方法。当我们关闭服务器的时候,它会自动的调用销毁方法destroy,而这个销毁方法也只会被调用一次。
- 在定义完Filter之后,Filter其实并不会生效,还需要完成Filter的配置,Filter的配置非常简单,只需要在Filter类上添加一个注解:
@WebFilter,并指定属性urlPatterns,通过这个属性指定过滤器要拦截哪些请求
当我们在Filter类上面加了@WebFilter注解之后,接下来我们还需要在启动类上面加上一个注解@ServletComponentScan,通过这个@ServletComponentScan注解来开启SpringBoot项目对于Servlet组件的支持。
1 |
|
- 在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:
chain.doFilter(request, response);
Filter细节
1、执行流程
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用
FilterChain对象当中的doFilter()方法,在调用doFilter()这个方法之前所编写的代码属于放行之前的逻辑。
在放行后访问完 web
资源之后还会回到过滤器当中,回到过滤器之后如有需求还可以执行放行之后的逻辑,放行之后的逻辑我们写在doFilter()这行代码之后。
init和destroy方法会被默认实现
1 |
|
浏览器控制台:
1 | DemoFilter 放行前逻辑..... |
2、拦截路径
执行流程我们搞清楚之后,接下来再来介绍一下过滤器的拦截路径,Filter可以根据需求,配置不同的拦截资源路径:
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
3、过滤器链
最后我们在来介绍下过滤器链,什么是过滤器链呢?所谓过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个Filter,放行之后再来执行第二个Filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,按照我们刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
先要执行过滤器2放行之后的逻辑,再来执行过滤器1放行之后的逻辑,最后在给浏览器响应数据。
以上就是当我们在web应用当中配置了多个过滤器,形成了这样一个过滤器链以及过滤器链的执行顺序。下面我们通过idea来验证下过滤器链。
验证步骤:
- 在filter包下再来新建一个Filter过滤器类:AbcFilter
- 在AbcFilter过滤器中编写放行前和放行后逻辑
- 配置AbcFilter过滤器拦截请求路径为:/*
- 重启SpringBoot服务,查看DemoFilter、AbcFilter的执行日志
AbcFilter过滤器
1 |
|
DemoFilter过滤器
1 |
|
通过控制台日志的输出,发现AbcFilter先执行DemoFilter后执行。
其实是和过滤器的类名有关系。以注解方式配置的Filter过滤器,它的执行优先级是按时过滤器类名的自动排序确定的,类名排名越靠前,优先级越高。
假如我们想让DemoFilter先执行,怎么办呢?答案就是修改类名。
测试:修改AbcFilter类名为XbcFilter,
1 |
|
运行程序查看控制台日志,发现XbcFilter先执行DemoFilter前执行
具体实现
登录校验的基本流程:
要进入到后台管理系统,我们必须先完成登录操作,此时就需要访问登录接口login。
登录成功之后,我们会在服务端生成一个JWT令牌,并且把JWT令牌返回给前端,前端会将JWT令牌存储下来。
在后续的每一次请求当中,都会将JWT令牌携带到服务端,请求到达服务端之后,要想去访问对应的业务功能,此时我们必须先要校验令牌的有效性。
对于校验令牌的这一块操作,我们使用登录校验的过滤器,在过滤器当中来校验令牌的有效性。如果令牌是无效的,就响应一个错误的信息,也不会再去放行访问对应的资源了。如果令牌存在,并且它是有效的,此时就会放行去访问对应的web资源,执行相应的业务操作。
- 所有的请求,拦截到了之后,都需要校验令牌吗?
- 答:登录请求例外
- 拦截到请求后,什么情况下才可以放行,执行业务操作?
- 答:有令牌,且令牌校验通过(合法);否则都返回未登录错误结果
具体流程
我们要完成登录校验,主要是利用Filter过滤器实现,而Filter过滤器的流程步骤:

代码实现
登录校验过滤器:LoginCheckFilter
1 |
|
在上述过滤器的功能实现中,我们使用到了一个第三方json处理的工具包fastjson。我们要想使用,需要引入如下依赖:
1 | <dependency> |
拦截器(Interceptor)
什么是拦截器?
- 是一种动态拦截方法调用的机制,类似于过滤器。
- 拦截器是Spring框架中提供的,用来动态拦截控制器方法的执行。
拦截器的作用:
- 拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
在拦截器当中,我们通常也是做一些通用性的操作,比如:
我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
基本操作
定义拦截器
注册配置拦截器
自定义拦截器:实现HandlerInterceptor接口,并重写其所有方法
1 | //自定义拦截器 |
注意:
preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
postHandle方法:目标资源方法执行后执行
afterCompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器:实现WebMvcConfigurer接口,并重写addInterceptors方法
1 |
|
Interceptor细节
1、拦截路径
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过addPathPatterns("要拦截路径")方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。
1 |
|
在拦截器中除了可以设置/**拦截所有资源外,还有一些常见拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
2、执行流程
介绍完拦截路径的配置之后,接下来我们再来介绍拦截器的执行流程。通过执行流程,大家就能够清晰的知道过滤器与拦截器的执行时机。
当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于我们当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问我们所定义的controller当中的接口方法。
Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
当我们定义了拦截器后,会在执行Controller的方法之前,请求被拦截器拦截住。执行
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。在controller当中的方法执行完毕之后,再回过来执行
postHandle()这个方法以及afterCompletion()方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
过滤器和拦截器之间的区别:
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
具体实现
登录校验的业务逻辑和登录校验Filter过滤器当中的逻辑是完全一致的。现在我们只需要把这个技术方案由原来的过滤器换成拦截器interceptor就可以了。
登录校验拦截器
1 | //自定义拦截器 |
注册配置拦截器
1 |
|
异常处理
我们来看一下出现异常之后,最终服务端给前端响应回来的数据长什么样。
1 | {"timestamp:"2022-12-09Te6:05:34.323+00:00","status":"500","error ":"Internal Server Error","path" "/depts""] |
响应回来的数据是一个JSON格式的数据。但这种JSON格式的数据显然并不是我们开发规范当中所提到的统一响应结果Result
由于返回的数据不符合开发规范,所以前端并不能解析出响应的JSON数据。
出现异常之后,当前案例项目的异常没有做任何的异常处理
当我们没有做任何的异常处理时,我们三层架构处理异常的方案:
- Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。
- service 中也存在异常了,会抛给controller。
- 而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。
解决方案
那么在三层构架项目中,出现了异常,该如何处理?
- 方案一:在所有Controller的所有方法中进行try…catch处理
- 缺点:代码臃肿(不推荐)
- 方案二:全局异常处理器
- 好处:简单、优雅(推荐)
全局异常处理器
我们该怎么样定义全局异常处理器?
- 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解
@RestControllerAdvice,加上这个注解就代表我们定义了一个全局异常处理器。 - 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解
@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
1 | //表示当前类为全局异常处理器 |
@RestControllerAdvice=@ControllerAdvice+@ResponseBody处理异常的方法返回值会转换为json后再响应给前端
此时,出现异常之后,异常已经被全局异常处理器捕获了。然后返回的错误信息,被前端程序正常解析,然后提示出了对应的错误提示信息。
静态资源的上传与访问
在BlessingChess项目中,想要做一个图片实时上传和读取的需求,第一想到的是直接把文件放在static目录下,然后实时上传和读取。
读取资源(也就是web端访问static资源)其实就很简单,Spring Boot 默认就配置了 /static/** 映射,所以无需任何配置就能访问。
很快啊,工具类起手:
1 | package com.example.BlessingChess.utils; |
这还没有问题,但是当实际测试的时候,发现新上传的文件,无法访问到,会报错NoResourceFoundException
资源的实时访问问题,比如上传图片后,然后再访问,可能需要重启才能继续访问,
jar对resources目录进行保护措施,可能读取不到上传的资源
但是有些极少量的文件需要存储到resources目录下,这就需要先获取到reources下的相应目录,此时应该考虑将来运行jar包时不能出错
因此推荐一下两种方式获取static目录:
通过ResourceUtils工具获取static目录
1
2
3
4
5
6try {
File staticDir = new File (ResourceUtils.getURL("classpath:static").getPath());
} catch (FileNotFoundException e) {
// static 目录不存在!
e.printStackTrace();
}通过 ClassPathResource 获取
1 | // 具体到要访问的文件,然后拿到文件流对象 |
当然,更好的方法是避开static目录存储,考虑做成本地硬盘上的映射目录:
添加配置文件WebMVCConfig,然后在添加资源映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36package com.example.BlessingChess.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
/**
* HttpConverterConfig 类,用于配置Web应用程序的HTTP转换器和资源处理器。
* 实现WebMvcConfigurer接口以自定义Spring MVC的默认配置。
*
* @author LXY
* @version 1.0
* @since 2024-02-20
*/
public class HttpConverterConfig implements WebMvcConfigurer {
/**
* 上传和读取图片的目录路径。
* 该目录应存在且应用程序应具有写入权限。
*/
public static final String uploadDirectory = "image/";
/**
* 配置资源处理器,用于从指定目录提供静态资源。
*
* @param registry 资源处理器注册表,用于注册资源处理器
*/
public void addResourceHandlers(ResourceHandlerRegistry registry) {
System.out.println("file:" + uploadDirectory);
registry.addResourceHandler("/image/**").addResourceLocations("file:" + uploadDirectory);
}
}这里会把**通配符给映射到后面那个目录后面
比如:
http://localhost:8080/image/icon/0/icon.jpg会被映射成file:E:/StudentOnline/BlessingChess/image/icon/0/icon.jpg这时候,你可以实时修改该目录里的内容,也可以实时访问。
还没完,当你用浏览器访问的时候,控制台又报错了:
corg.springframewOPk.web.servlet.nesounce.NOResourceFoundException: No static resource favicon.ico.
这不是代码的问题,而是用浏览器请求资源时,都会同时请求标签页图标,当你在postman请求资源时就不会发生这个问题了,或者直接在static目录下放一个favicon.ico文件也行
关于相对路径:
./**代表的是E:,src的同级路径,这个./也可以直接省略
序列化和反序列化
Java 序列化是一种将对象转换为字节流的过程,以便可以将对象保存到磁盘上,将其传输到网络上,或者将其存储在内存中,以后再进行反序列化,将字节流重新转换为对象。
序列化在 Java 中是通过 java.io.Serializable 接口来实现的,该接口没有任何方法,只是一个标记接口,用于标识类可以被序列化。
当你序列化对象时,你把它包装成一个特殊文件,可以保存、传输或存储。反序列化则是打开这个文件,读取序列化的数据,然后将其还原为对象,以便在程序中使用。
传输对象
实现 Serializable 接口:
要使一个类可序列化,需要让该类实现 java.io.Serializable
接口,这告诉 Java 编译器这个类可以被序列化.
1 | public class User implements java.io.Serializable { //该接口没有任何方法,只是一个标记接口,用于标识类可以被序列化。 |
java.io.ObjectOutputStream
代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obi对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream
代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
通过Socket传输对象
客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class userClient {
public static void main(String[l args){
//创建客户端socket,指定服务器的p和端口
try {
Socket socket = new Socket("127.0.0.1",9999);
//获取该socket的输出流,用来向服务器发送信息
OutputStream os=socket.getOutputStream();
ObiectOutputStream oos =new ObjectOutputStream(os);
//序列化user对象,以字节序列输出
oos.writeObject(new User(1, "root","123456"));
socket.shutdownOutput();
//获取输入流,取得服务器的信息
InputStream is= socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String info = null;
while ((info = br.readLine())!= null){
System.out.println("服务器的信息是:"+ info)
}
}
}服务端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class ServerHandleThread implements Runnable{ //表示该类的实例可以被一个线程执行
Socket socket=null;
public ServerHandleThread(Socket socket){
super();
this.socket= socket;
}
public void run() {
OutputStream os = null;
PrintWriter pw = null;
try {
InputStream is = socket.getInputStream();
ObjectInputStream ois=new ObjectInputStream(is);
//从客户端读取字节序列,反序列化为对象
System.out.println("客户端发送的对象:"+(User) ois.readObject());
socket.shutdownInput();// 关闭套接字的输入流,连接并未关闭
os=socket.getOutputStream();
pw=new PrintWriter(os);
pw.println("欢迎登录!");
pw.flush();
socket.shutdownOutput();
}
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public class simpleServer {
public static void main(String[] args){
try {
ServerSocket serverSocket =new ServerSocket(9999);
intcount=0://记录客户端的数量
System.out.println("服务器启动,等待客户端的连接。。。");
Socket socket = null;
while(true){
socket=serverSocket.accept();
++count;
//调用线程函数
Thread serverHandleThread=new Thread(new ServerHandleThread(socket));
serverHandleThread.setPriority(4);
serverHandleThread.start();
System.out.println("上线的客户端有"+ count+"个!");
InetAddress inetAddress=socket.getInetAddress();
System.out.println("当前客户端的!P地址是:"+inetAddress.getHostAddress());
}
}catch(lOException e){
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
存储对象
序列化对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = new Employee();
e.name = "Reyan Ali";
e.address = "Phokka Kuan, Ambehta Peer";
e.SSN = 11122333;
e.number = 101;
try
{
FileOutputStream fileOut =
new FileOutputStream("/tmp/employee.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in /tmp/employee.ser");
}catch(IOException i)
{
i.printStackTrace();
}
}
}- 当序列化一个对象到文件时, 按照 Java 的标准约定是给文件一个 .ser 扩展名
反序列化对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import java.io.*;
public class DeserializeDemo
{
public static void main(String [] args)
{
Employee e = null;
try
{
FileInputStream fileIn = new FileInputStream("/tmp/employee.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
e = (Employee) in.readObject();
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return;
}catch(ClassNotFoundException c)
{
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("Address: " + e.address);
System.out.println("SSN: " + e.SSN);
System.out.println("Number: " + e.number);
}
}
- 本文作者: NICK
- 本文链接: https://nicccce.github.io/TechNotes/Youth-Feed-Backen/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!